架构整洁之道--边界
![]()
上一篇《架构整洁之道(上) — 基础准备篇》中我们介绍了架构的一些基本概念和设计原则, 最后还学习了关于组件构建的一些原则. 这一篇我们来讲讲组件的边界划分.
边界
正如上一篇提到过的, 软件架构所追求的目标是最大限度地降低构建和维护一个系统所需的资源. 而这其中最消耗我们人力资源的又是什么? 答案是系统中存在的耦合 — 尤其是那些过早作出的不成熟的决策所导致的耦合. 也就是那些和系统的业务需求(用例除外)无关的决策, 包括我们要采用的框架、数据库、Web服务器、工具库、依赖注入等.
在一个设计良好的系统架构中, 这些细节性的决策都应该是辅助性且可被推迟的, 我们的架构设计不应该依赖于这些细节, 而要尽可能的推迟这些细节性的决策, 并致力于将这种推迟所产生的影响降到最低.
所以如何将软件分割成各种元素, 以便约束元素之间的依赖关系就尤为重要了. 而边界的作用就在于此. 可以说软件架构设计的本身就是一门划分边界的艺术.
所谓的边界划分, 就是指在组件间建立变更的防火墙. 我们称在运行时, 一个组件调用另一个组件的函数并传递数据(或者说边界两侧函数调用和数据传递)的行为为跨边界调用.由于一个组件的源码变更会导致其他组件的源码也有可能会随之发生变更和重新编译, 所以要处理好跨边界调用就需要对源码中的依赖关系进行合理管控.
边界的形式
一个系统的架构是有组件以及他们之间的边界共同定义的. 那么这些边界又有哪些存在的形式呢?
源码层次上的解耦模式
最简单、最常见的架构边界通常并没有一个固定的物理形式, 他们只是对一个进程、同一个地址空间内的函数和数据进行某种划分, 也就是源码层次上的解耦模式. 从部署角度看, 最后都产生了一个单独的可执行文件—也就是所谓的单体结构.
这类架构一般都需要利用某种动态形式的多态来管理其内部的依赖关系(这也是面向对象编程这类编程范式进几十年来一直是主流的原因).最简单的跨边界调用是由低层客户端来调用高层服务函数, 这种依赖关系在运行时和编译时都会保持一致.
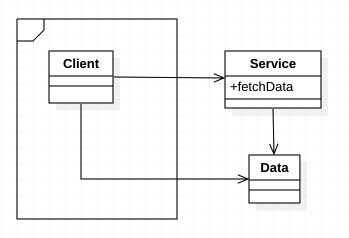
但当高层组件的客户端需要调用底层组件的服务时, 我们就需要运用动态形式的多态来反转依赖关系了. 这种情况下, 运行时和编译的依赖关系就是相反的.
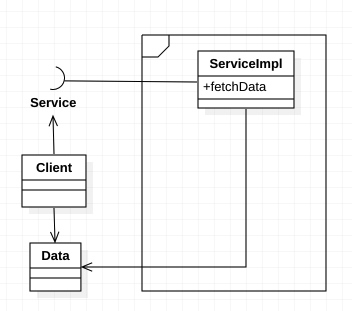
这种自律的组件划分可以极大地帮助整个项目的开发、测试和部署, 使不同团队可以同时开发不同的组件不会相互干扰. 高层组件与低层细节之间也可以得到良好的隔离, 独立演进.
部署层次的解耦模式
与单体架构类似, 其所有的函数仍然处于同一个进程、同一个地址空间中. 管理组件划分依赖关系的策略也基本一致. 不同的是这种模式将其所有可部署的单元打包成一个便于操作的文件格式, 不需要重新编译就可以交付的形式(二进制或其他等价的可部署形式), 比如最常见的物理边界形式—动态链接库.
本地进程
系统架构还有一个更明显的物理边界形式:本地进程. 每个本地进程既可以是一个静态链接的单体结构 也可以是由多个动态链接组件构成的程序. 我们可以将本地进程看成膜中超级组件, 该进程由一系列的较低层次的组件组成, 我们将通过动态形式的多态来管理他们之间的依赖关系, 本地进程的隔离策略也与单体结构和动态链接库基本相同, 其源码中的依赖关系也是始终由低层组件指向高层策略. 对本地进程来说, 高层进程的源码中不应该包含低层进程的名字、物理内存地址或注册表键名. 应该让低层进程成为高层进程的一个插件.
本地进程跨边界调用需要用到系统调用、数据编/解码、进程上下文切换, 成本相对于单体架构和动态链接库的直接函数调用要高一些, 所以需要谨慎控制通信的次数.
服务
系统架构中最强的边界形式就是服务. 服务可以是一个进程, 通常由命令行环境或其他等价的系统调用来生成. 但服务并不依赖于具体的运行为主, 两个相互通信的服务可以处于单一物理处理器/多喝系统的同一组处理器上, 也可以处于不同处理器上.
与本地进程类似我们在划分架构边界的时候, 应让低层次的服务作为高层次服务的插件, 确保高层次的服务源码中没有包含任何低层服务相关的物理信息(URI等).
无论服务还是本地进程, 他们都是由一个或多个源码组件组成的单体结构, 或者一组动态链接的可部署组件, 这也就意味着系统通常会同时包含高通信量、低延迟的本地架构边界; 和低通信量、高延迟的服务边界.
服务化的问题
无论从系统架构的意义还是通过服务化这种形式隔离不同平台/进程中的程序行为都是一件重要的事情, 但这并不意味着我们应该服务化就是”银弹“, 也不意味着服务化本身没有问题.在极端情况下, 客户端和服务端甚至可能会由于耦合过于紧密而不具备系统架构意义上的隔离性.
解耦的谬论
很多时候我们在讨论服务化的好处的时候, 都在强调它将系统拆分后实现了强解耦. 从一定程度上讲是的, 毕竟每个服务都是以不同进程/不同处理器/物理机来运行, 彼此不能直接访问服务间的变量; 然而, 他们之间还是可能会有处理器内地共享资源, 或通过网络共享的资源而彼此耦合. 而任何形式的共享数据行为都会导致强耦合.
例如: 如果给服务间传递的数据结构中新增一个字段, 那么每个操作之歌字段的服务就必须作出更改, 服务之间必须对这条数据的解读达成一致.这里的服务就强耦合于这条数据结构.
而服务的接口与普通函数接口相比, 并没有比后者更正式、更严谨和更好.
独立部署的谬论
我们在吹嘘服务化的好处时另一个通常会说的是, 不同服务可以由不同的专职团队负责和运维.这让团队可以采用dev-ops 混合的形式来编写和维护或运维各自的服务.这种开发和部署上的独立性可以被认为是可扩展的.
但是抛开大型系统可以同样采用单体或组件模式来构建外, 我们上面说过拆分服务并不意味着这些服务就可以彼此独立, 如果这些服务之间以数据或行为形式相耦合那么他们的开发、部署、和运维也必须彼此协调来进行.
不完全边界
构建完整的架构边界是一件很耗时耗力的事. 在这个过程中需要为系统设计双向的多态边界接口, 用于输入和输出的数据结构以及相关的依赖关系管理. 这里会涉及大量的前期工作和后期维护工作.而一位优秀的架构师在认识设计架构边界成本太高后, 为了将来的可能需要, 通常还是会希望预留一个边界. 即便这种预防性的实际违背了YAGNI(You Aren’t Going to Need It)原则, 而被敏捷社区所诟病. 然而架构的工作本身就咬做这样的预见性设计, 这时候, 我们就需要引入不完全边界(partial boundary).
省略多组件的管理部分
简单的说这种方式就是将系统分割成一系列可以独立编译、独立部署的组件后, 再把他们构建成一个组件. 显然这种不完全边界所需的代码量和设计工作, 和设计完整的边界时是完全一样的. 它只是省去了多组件管理这部分的工作(包括版本号管理、发布管理等).
单向边界
在设计一套完整的系统架构边界时, 往往需要反向接口来维护边界两侧组件的隔离性. 而且这一般不是一次性工作, 需要我们持续长期的投入.
而单向边界就是用临时的占位、将来可被替换成完整架构边界的单向边界设计, 简单来说就是完整边界设计的部分实现. 由于没有采用双向反向设计, 这部分只能依赖开发者和架构师的自律来保证组件的持久隔离性.
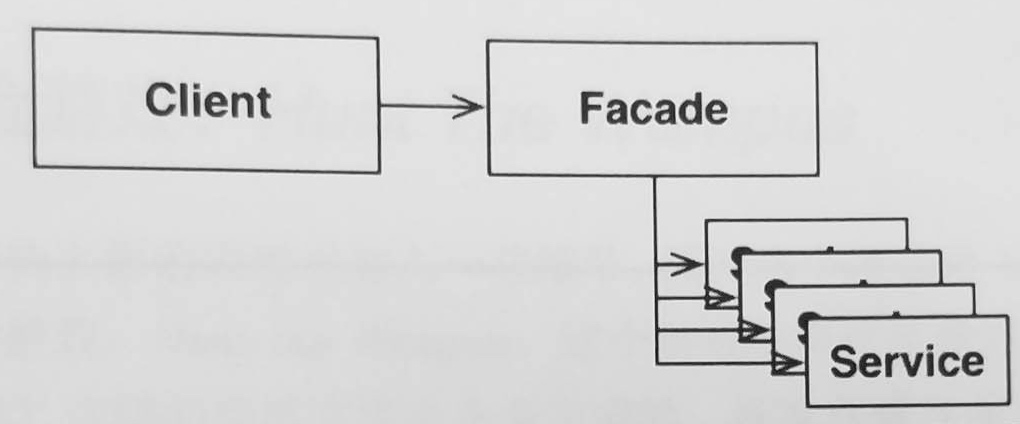
门户模式
还有一种更简单的架构边界设计: *门户模式(facade pattern).*这种模式下我们连依赖反转的工作都可以省略. 这里的边界都只能由Facade类来定义, 它会负责将 Client 的调用传递给 Client 不可见的服务函数.
测试边界
和程序代码一样, 测试代码也是系统的一部分.本质说, 测试组件也是要遵循依赖关系原则的, 它始终是内向依赖于被测试部分的代码的, 同时系统中没有其他组件依赖于它们. 另一方面, 测试组件也是可以独立部署(事实上大部分测试组件都被部署在测试环境, 而在生产环境中剥离).
脆弱的测试问题
由于测试代码与系统是强耦合的, 它就随着系统的变更而变更. 哪怕系统中组件的一点小变化, 都可能导致许多与之相耦合的测试出现问题, 需要作出相应的变更. 而严重的情况, 修改一个通用的系统组件可能导致成百上千的测试除夕问题, 我们通常成这类问题为脆弱的测试问题(fragile tests problem). 而这类问题往往还会让系统变的非常死板. 当开发者意识到一些简单的修改会导致大量的测试出错的时候, 他们自然就会抵制修改.
要想解决这个问题, 就必须在设计中考虑到系统的可测试性. 软件设计的第一条原则(不管是未来可测试性还是其他)是不变的: 不要依赖于多变的东西. 譬如GUI是多变的, 我们在系统设计的时候应该让业务逻辑不通过GUI也可以被测试.为测试建立专门验证业务逻辑的测试创建一个API.

架构整洁之道 --- 基础准备篇
![]()
架构一词相信很多技术开发的同学在工作中经常接触到, 甚至于不少同学在求职简历中介绍自己工作的内容有不少也写着譬如架构改进相关的术语. 但对于架构的工作理论知识却知之甚少, 更多的还停留在“构造文件夹”的层面. 在阅读本文之前我们不妨来尝试回答一下问题.
- 什么是你理解的架构, 架构的价值在哪里.
- 你简历中的架构改进, 主要做了哪些工作.
- 你知道哪些架构模式, 有哪些架构设计中的原则, 你在做架构设计的时候是如何进行的.
- 分层架构里你通过什么去界定每一层.
这个系列将通过介绍架构相关的知识, 来尝试性给这些问题提供回答的方向.
下面是准备篇的内容
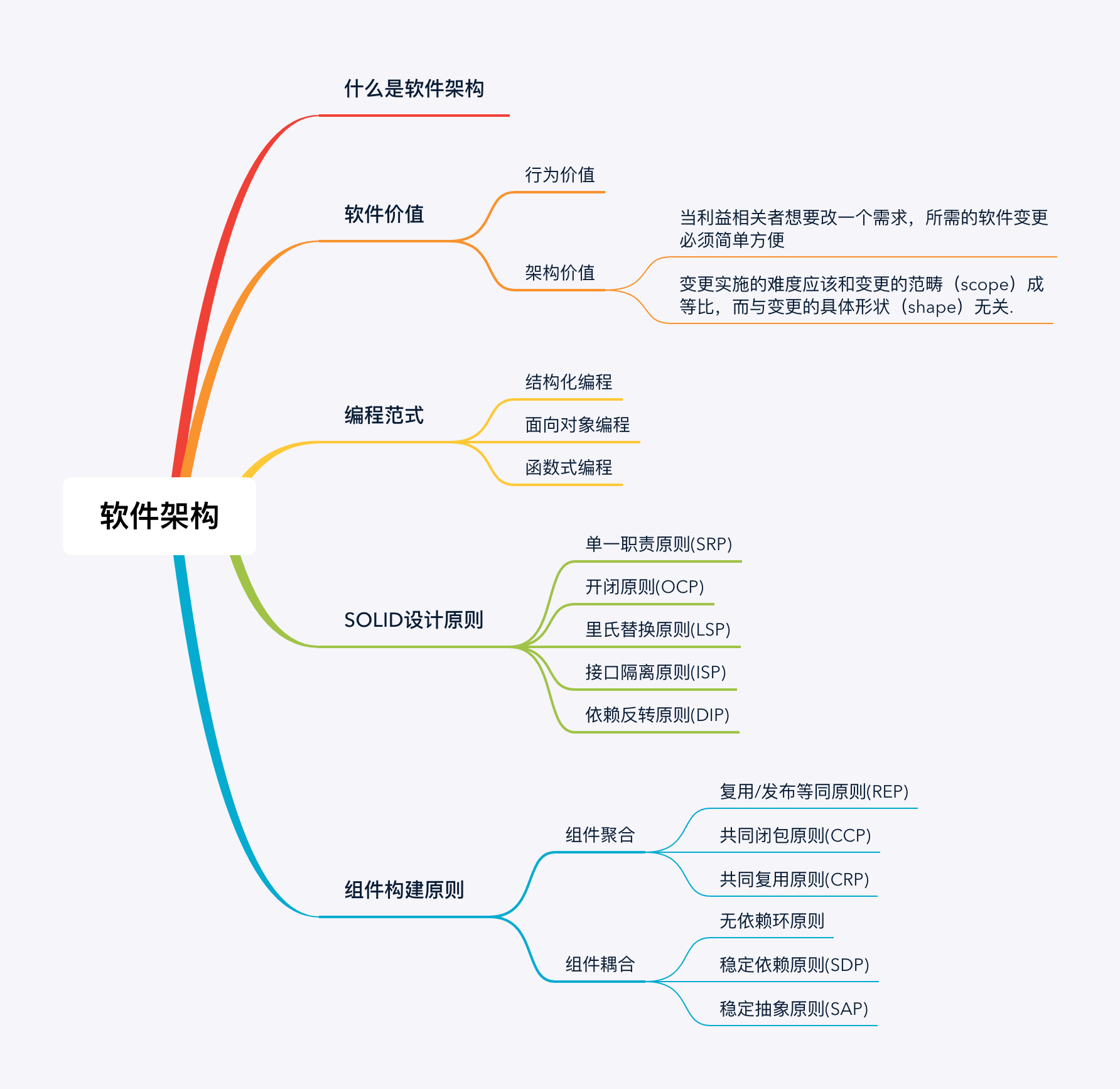
什么是软件架构
**架构(architecture)**一词大概是源于建筑学,也常指建筑物在其尺度上是如何依靠内部的支撑物相互结合而稳固构造的方式。
**软件架构(software architecture)**是一系列相关的抽象模式,用于指导大型软件系统各个方面的设计. 而广义的理解这里的抽象模式不仅仅只是技术的选型, 框架的输出. 它应该是贯穿在整个问题解决方案的方方面面, 包括对技术的组织, 业务的组织, 资源(包括人员)的组织. 本文下面所有的"架构"一词不做特殊说明都是指软件架构中对系统或工程的组织.
软件架构的价值和目标
既然要聊是软件架构的价值, 那首先我们要了解软件系统的价值所在. 软件(Software)的价值有两方面:行为价值(表现)和架构价值(结构). 这也是对 software 这个词的拆解:
- 行为价值
ware表示商品, 也就是软件所表现出的商品属性. 也就是软件的表现, 包括需求的实现, 以及可用性保障(性能、功能可用性等). - 架构价值
soft 表示软件的结构可扩展易修改属性. 可以从两方面理解- 当利益相关者想要改一个需求,所需的软件变更必须简单方便;
- 变更实施的难度应该和变更的范畴(scope)成等比,而与变更的具体形状(shape)无关.
在我看来这两个价值关系就像“鹅与金蛋”的关系: 行为价值代表着‘产量’, 决定了利益相关者的实际收益; 架构价值代表‘产能’, 它为行为价值提供支撑, 提升软件系统的服务能力和生产效率. 在实际生产中关键是找准两者的平衡点, 平衡点是对投入产出比的考量、对现有资源的妥协, 而这本身也是架构工作的一部分.
至于架构的目标就是为了实现架构的价值, 通俗的讲就是用更少的资源构建软件系统实现需求(它应该贯穿于软件系统的开发、部署、运行、维护等整个生命周期).而一般情况下, 我们为软件构建中层结构的主要目标
- 使软件可容忍被改动
- 使软件更容易理解
- 构建可在多个软件系统中复用的组件
一个软件架构的优劣, 可以用它满足用户需求所需要的成本来衡量. 如果在系统的整个生命周期内一直维持低成本, 那么这个系统设计就是优良的. 那么我们应该如何设计一个优良的架构呢?
好的架构从代码开始
任何软件架构的实现都依赖于具体的代码, 所以要想构建好的软件系统, 应该从整洁的代码开始.
毕竟建筑设计的再好, 如果使用的砖头质量不好, 架构能起到的作用也是微乎其微的. 同时如何组织这些砖头也很大程度上决定了建筑的整体质量. 在软件编程领域编程范式和SOLID 设计原则给了很好的理论指导和实践基础.
编程范式
编程范式 (paradigm) 指的是程序的编写模式.
其实所谓架构就是限制,限制源码放在哪里、限制依赖、限制通信的方式,但这些限制比较上层。编程范式是最基础的限制,它限制我们的控制流和数据流:
结构化编程对程序控制权的直接转移进行了限制和规范;面向对象编程对程序控制权的间接转移进行了限制和规范;函数式编程对程序中的赋值进行了限制和规范;
SOLID设计原则
SOLID原则的主要作用就是告诉我们如何将数据和函数组织成为类(这里的类区别于面向对象编程中的类, 它代表了一种数据和函数的分组),以及如何建这些累链接起来成为程序.
单一职责原则(SRP)
任何一个软件模块都应该只对某一类行为负责. 该设计是基于康威定律(Conway’s Law)的一个推论 — 一个软件系统的最佳结构高度依赖于开发这个系统的组织内部结构.
开闭原则(OCP)
设计良好的计算机软件应该易于扩展, 同时抗拒修改.
里氏替换原则(LSP)
如果想用可替换的组件来构建软件系统, 那么这些组件必须遵循同一个约定, 以便让这些组件可以相互替换.
接口隔离原则(ISP)
该设计原则主要告诫软件设计师应该在设计中避免不必要的依赖.
依赖反转原则(DIP)
该设计原则指出高层策略性的代码不应该依赖底层实现细节, 相反实现底层细节的代码应该依赖高层策略性代码.
组件构建原则
当然, 正如一块好砖也会盖歪楼一样, 采用良好的中层组件并不能保障系统的整体运作良好. 所以有必要再针对组件的设计原则进一步的讨论. 如果说SOLID原则是指导我们如何将砖砌成墙和房间, 那么组件构建原则就是指导我们如何将这些房间组合成房子.
组件聚合
那么哪些类应该被合成一个组件? 这是一个非常重要的设计决策 应该遵循优秀的软件工程经验, 下面介绍三个与构建组件相关的基本原则:
复用/发布等同原则(REP)
软件复用的最小力度应等同于其发布的最小粒度.
共同闭包原则(CCP)
我们应该将哪些会同时修改, 并且为相同目的而修改的类放到一个组件中, 而将不同时修改或不会为了相同目的而修改的类放到不同组件中.
共同复用原则(CRP)
不要强迫一个组件的用户依赖他们不需要的东西.
仔细的读者大概已经意识到这三个原则之前是存在竞争的关系. REP 和 CCP 原则是粘合性原则, 而 CRP 原则是排除性原则. 架构的工作就要在这三个原则中进行取舍, 优秀的架构师应该在这三角区域中定位一个最适合当前研发团队的位置, 同时根据时间和实际情况不停调整. 组件的构成安排应该随着项目重心的不同, 以及研发性和复用性的不同而不断演化.
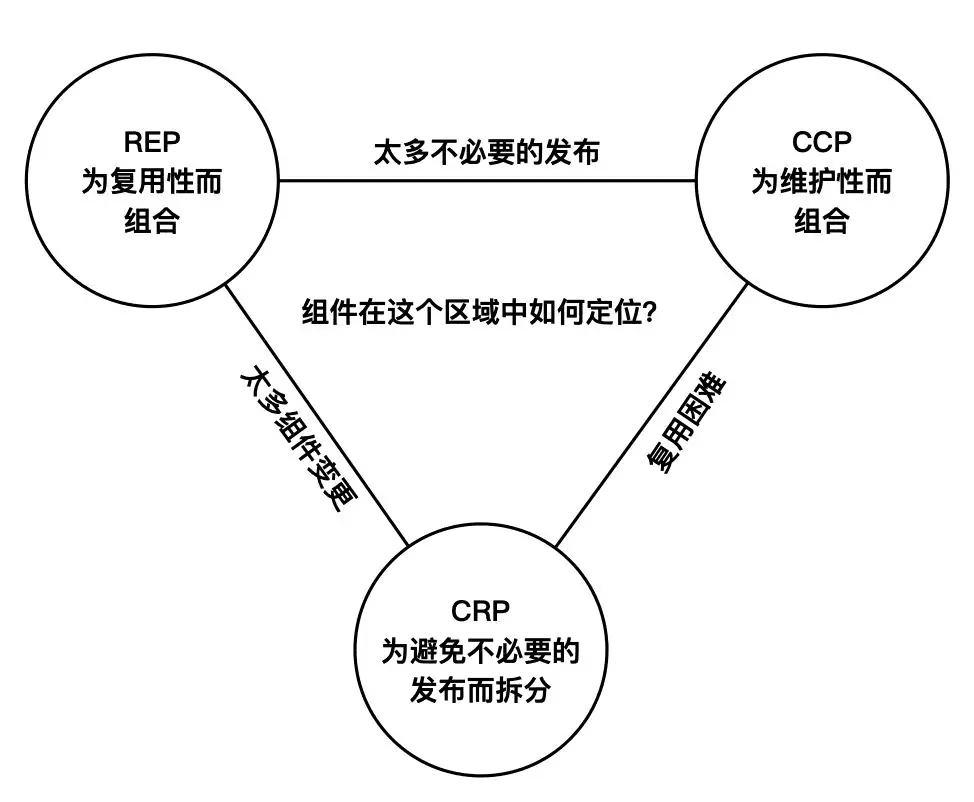
组件耦合
按上面的原则类被合成一个个组件, 那么组件间的关系又该如何处理.
无依赖环原则
组件依赖关系图中不应该出现环.
针对每周构建中通过频繁的构建影响高效率开发, 延长构建时间间隔影响项目质量, 增大风险的情景, 通过独立组件发布可以消除影响, 但必须保障组件间没有依赖环. 可以通过依赖反转原则DIP和创建共同依赖的新组件的方式来解决.
稳定依赖原则(SDP)
依赖关系必须要指向更稳定的方向.
这里组件的稳定性指的是它的变更成本,和它变更的频繁度没有直接的关联(变更的频繁程度与需求的稳定性更加相关). 那么, 如何衡量一个组件的稳定性呢? 其中一种方法是计算所有入和出的依赖关系.
入向依赖(Fan-in)这个指标指带了组件内部类的数量.出向依赖(Fan-out)指代组件内部类依赖于组件外部类的数量.不稳定性(I) I=Fon-out/(Fan-in + Fon-out).
如果发现违反稳定依赖原则的地方,解决的办法也是通过 DIP 来反转依赖
稳定抽象原则(SAP)
一个组件的抽象化程度应该与其稳定性保持一致.
为了防止业务决策和架构设计经常变更, 我们需要把代表系统高阶决策的组件放到稳定组件中. 然而如果我们这么做, 那么用于秒杀那些策略的源代码就难以修改. 为了防止高阶策略难以修改,根据开闭原则OCP通常我们应该抽象出稳定的接口、抽象类为单独的组件,让具体实现的组件依赖于接口组件,这样它的稳定性就不会影响它的扩展性.
衡量抽象化程度: A=Na/Nc (其中 Nc 代表组件中类的数量, Na 代表组件中抽象类和接口的数量)
将不稳定性(I)作为横轴,抽象程度(A)作为纵轴,那么最稳定、只包含抽象类和接口的组件应该位于左上角(0,1),最不稳定、只包含具体实现类,没有任何接口的组件应该位于右下角(1,0),他们连线就是主序列线,位于线上的组件,他们的稳定性和抽象程度相匹配,是设计良好的组件。位于(0,0)周围区域的组件,它们是非常稳定(注意这里的稳定指的是变更成本)并且非常具体的组件,因为他们的抽象程度低,决定了他们经常改动的命运,但是又有许多其他组件依赖他们,改起来非常痛苦,所以这个区域叫做痛苦区。右上角区域的组件,没有其他组件依赖他们,他们自身的抽象程度又很高,很有可能是陈年的老代码,所以这个区域叫做无用区。
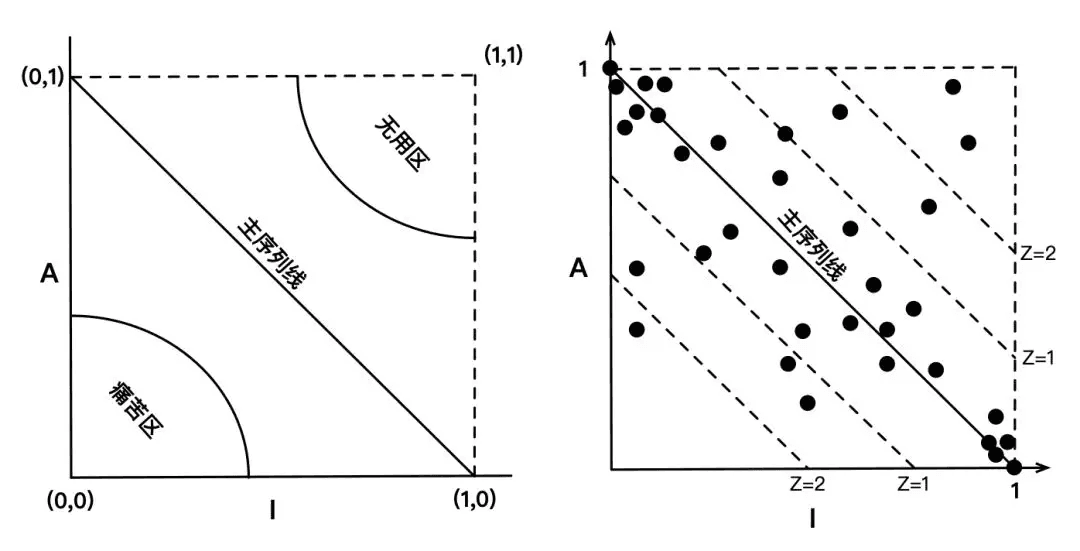 另外,可以用点距离主序列线的距离 Z 来表示组件是否遵循稳定抽象原则,Z 越大表示组件越违背稳定依赖原则。
另外,可以用点距离主序列线的距离 Z 来表示组件是否遵循稳定抽象原则,Z 越大表示组件越违背稳定依赖原则。
参考
The Clean Code Blog
DYLD-符号绑定
![]()
系统环境
> ProductName: macOS
> ProductVersion: 11.0
> BuildVersion: 20A5343i
> Darwin Kernel Version 20.0.0: Thu Jul 30 22:49:28 PDT 2020; root:xnu-7195.0.0.141.5~1/RELEASE_X86_64 x86_64
引子
在软件工程的鸿蒙时代, 一个程序的所有源码都是在一个文件上的, 随着工程的扩大和代码量增加, 多人协同、代码复用、维护、编译时间等问题就日益突出了. 为了解决这些问题也就有了静态链接.
但是静态链接也还是存在着很多问题.比如典型的:空间浪费(包括内存和硬盘)、程序更新&部署不方便等.
动态链接的出现使得程序可以在运行时才进行链接, 很好的解决了上述问题. 动态链接的好处有很多,其中包括:
- 代码重用
常用的代码可以被提取到一个库中,然后共享使用。
- 易于更新
只要符号大体相同(API接口不变),驻留在库中的代码可以很容易地更新,库也可以被替换。
- 减少磁盘使用量
因为动态库中的代码并不会在每一个使用它的二进制中都要包含, 只有在程序运行时才会被链接到可执行文件中, 而不同的程序可以共享同一个动态库代码。
- 减少RAM的使用
这是它最重要的优势。一个库的副本可能会被mmap-ed到所有的进程中,而在RAM中实际只占用一次。库代码通常被标记为r-x(只读可执行),因此同一个物理副本被许多进程隐含地共享。
注: 同时动态链接的运行时特性赋予了我们很重要的能力–函数拦截、审计和HOOK。dyld允许通过环境变量–DYLD_INSERT_LIBRARIES(类似于ld的LD_PRELOAD)和DYLD_LIBRARY_PATH(类似于ld的LD_LIBRARY_PATH)–以及它的函数插值机制来实现HOOK和拦截; 此外你还可以直接通过修改符号表等来实现类似功能.后续可以单独开篇来讲解这方面的应用.
准备
因为整个符号绑定的流程比涉及面比较广, 在开始具体流程分析之前, 可能需要掌握一些准备知识和了解专业术语.
基本概念
Mach-O: Mach-O为Mach Object文件格式的缩写,它是一种用于可执行文件,目标代码, 动态库,内核转储的文件格式, 包括文中提及的镜像也是一种Mach-O文件.
dyld: Apple 生态操作系统(macOS、iOS)的动态链接器.
dylib: 动态库.
类似于Unix中的Shared Object。一个 MH_DYLIB (0x6)类型的Mach-O对象,通过LC_LOAD_DYLIB Mach-O命令或 dlopen API加载到其他可执行文件中。
符号(symbol): Mach-O文件中的一个变量或函数,在该文件之外可能可见,也可能不可见。
Binding(绑定): 将一个符号引用和它在内存中的地址连接起来。绑定可以是加载时的,懒惰的(延迟)或(缺失/可覆盖)。这些都可以在编译时控制:ld的 -bind_at_load 指定了加载时绑定,__attribute((weak_import))指定了弱符号。还有一个 ld 的 -prebind switch可以将库预绑定到固定地址.
启动流程
iOS中冷启动的大致流程如图(dyld2):

- 内核fork并创建程序进程
- 加载程序和依赖的动态库
- Rebase
- Binding
- ObjC runtime 初始化
- 其他初始化代码
dyld3中略有不同增加了缓存以及将解析Mach-O和查找依赖库符号的部分放到了out-of-process进行, 但总体上的流程没有太大变化.
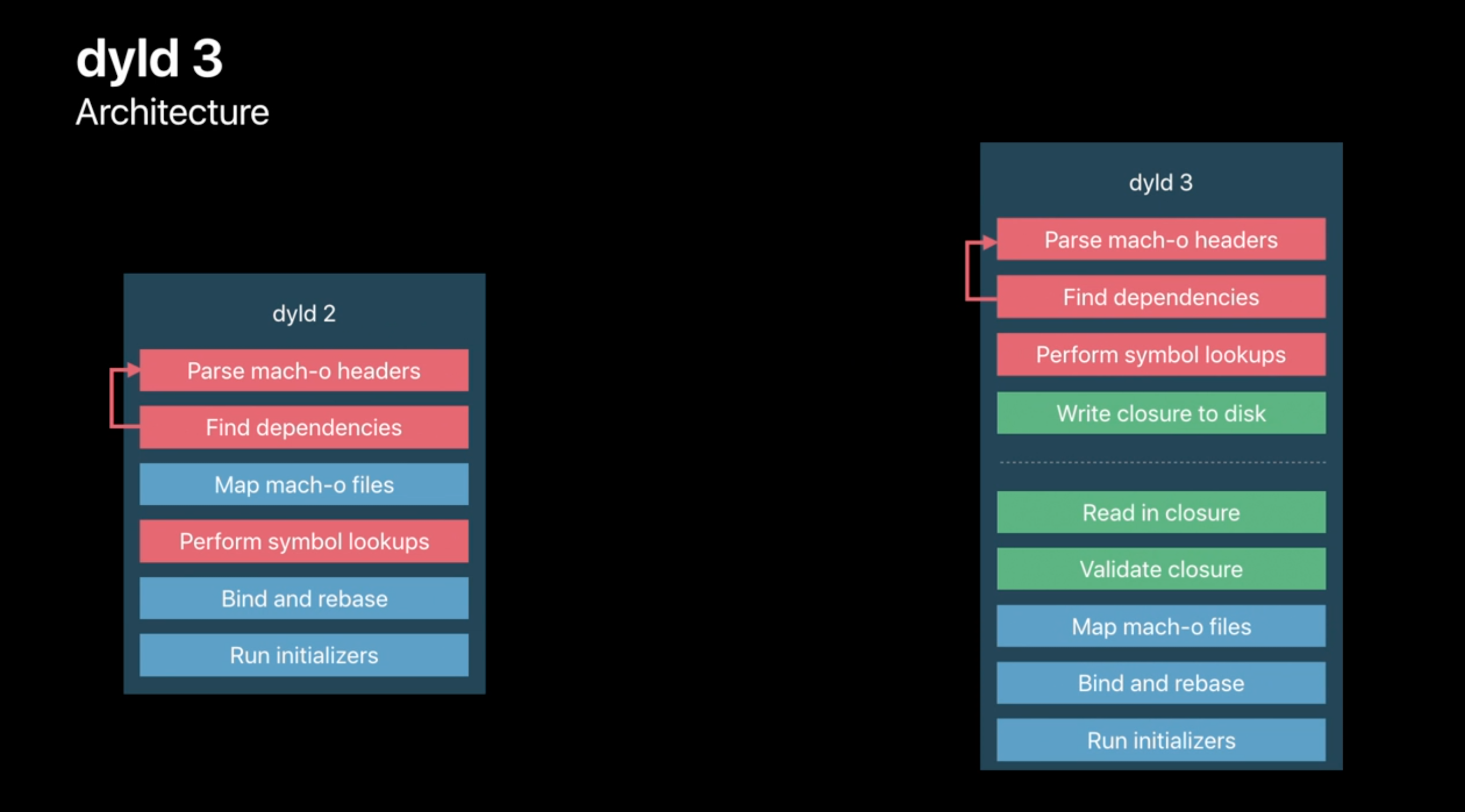
符号Binding
首先, 我们来创建一个简单的工程看下, 添加以下的代码.
- (void)viewDidLoad {
NSString *name = UIApplicationDidFinishLaunchingNotification;
printf("%s", name.UTF8String);
}
编译后, 可以通过otool工具查看其汇编代码:
$ otool -tv dyld-test
dyld-test:
...
(__TEXT,__text) section
-[ViewController viewDidLoad]:
0000000100001c60 pushq %rbp
0000000100001c61 movq %rsp, %rbp
0000000100001c64 subq $0x20, %rsp
0000000100001c68 movq 0x2391(%rip), %rax #_UIApplicationDidFinishLaunchingNotification
0000000100001c6f movq %rdi, -0x8(%rbp)
0000000100001c73 movq %rsi, -0x10(%rbp)
0000000100001c77 movq (%rax), %rax
0000000100001c7a movq %rax, %rdi
0000000100001c7d callq *0x2395(%rip)
0000000100001c83 movq %rax, -0x18(%rbp)
0000000100001c87 movq -0x18(%rbp), %rax
0000000100001c8b movq %rax, %rdi
0000000100001c8e callq 0x100002382
0000000100001c93 movq 0x7716(%rip), %rsi
0000000100001c9a movq %rax, %rdi
0000000100001c9d callq *0x2365(%rip)
0000000100001ca3 leaq 0x7ac(%rip), %rdi
0000000100001caa movq %rax, %rsi
0000000100001cad movb $0x0, %al
0000000100001caf callq 0x100002394 # call _print_stub
0000000100001cb4 xorl %ecx, %ecx
0000000100001cb6 movl %ecx, %esi
0000000100001cb8 leaq -0x18(%rbp), %rdx
0000000100001cbc movq %rdx, %rdi
0000000100001cbf movl %eax, -0x1c(%rbp)
0000000100001cc2 callq 0x10000238e
0000000100001cc7 addq $0x20, %rsp
0000000100001ccb popq %rbp
0000000100001ccc retq
0000000100001ccd nop
....
关注上面有备注的两行, 这两行指令分别引用了_UIApplicationDidFinishLaunchingNotification和_print符号. 那么按RIP-relative 寻址方式我们可以计算得到
> 0x100001c6f + 0x2391 = 0x100004000 = _UIApplicationDidFinishLaunchingNotification 目标虚拟地址
> 0x100002394 = 0x100001cb4 + 0x6d = _print函数目标虚拟地址
那么0x100001c6f和0x100002394在Mach-O中哪里呢? 通过otool -s或者MachOView我们可以找到这个两个地址分别在__DATA_CONST,__got和__TEXT,__stubs 的section中:
$ otool dyld-test -s __DATA_CONST __got
dyld-test:
Contents of (__DATA_CONST,__got) section
0000000100004000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000000100004010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000000100004020 00 00 00 00 00 00 00 00
$ otool -v dyld-test -s __TEXT __stubs
dyld-test:
Contents of (__TEXT,__stubs) section
0000000100002334 jmpq *0x5cc6(%rip)
000000010000233a jmpq *0x5cc8(%rip)
0000000100002340 jmpq *0x5cca(%rip)
0000000100002346 jmpq *0x5ccc(%rip)
000000010000234c jmpq *0x5cce(%rip)
0000000100002352 jmpq *0x5cd0(%rip)
0000000100002358 jmpq *0x5cd2(%rip)
000000010000235e jmpq *0x5cd4(%rip)
0000000100002364 jmpq *0x5cd6(%rip)
000000010000236a jmpq *0x5cd8(%rip)
0000000100002370 jmpq *0x5cda(%rip)
0000000100002376 jmpq *0x5cdc(%rip)
000000010000237c jmpq *0x5cde(%rip)
0000000100002382 jmpq *0x5ce0(%rip)
0000000100002388 jmpq *0x5ce2(%rip)
000000010000238e jmpq *0x5ce4(%rip)
0000000100002394 jmpq *0x5ce6(%rip)
实际上, Mach-O中的 __TEXT section对外部符号的引用地址也就是指向这两个section.
__DATA_CONST,__got: no-lazy symbol pointer, 比如全局变量/常量、dyld中的函数符号.__TEXT,__stubs: lazy symbol stub, 比如其他动态库中的函数符号.
section(__DATA_CONST __got)
可以把section(__DATA_CONST __got)看做一个表, 每个条目是一个地址值.但是上面的结果我们可以看到0x100004000对应的内容都是0.所以dyld需要在运行时用实际的符号地址替换.这也是该section被定义在__DATA segment中的原因了.
那么dyld又是如何获取每个条目的符号信息的呢? 按我的理解至少要该条目的符号名称以及所在的库.
我们知道Mach-O中每个segment都是由LC_SEGMENT定义的, 该命令结束后的阐述描述了section的信息对应的数据结构是:
struct section_64 { /* for 64-bit architectures */
char sectname[16]; /* name of this section */
char segname[16]; /* segment this section goes in */
uint64_t addr; /* memory address of this section */
uint64_t size; /* size in bytes of this section */
uint32_t offset; /* file offset of this section */
uint32_t align; /* section alignment (power of 2) */
uint32_t reloff; /* file offset of relocation entries */
uint32_t nreloc; /* number of relocation entries */
uint32_t flags; /* flags (section type and attributes)*/
uint32_t reserved1; /* reserved (for offset or index) */
uint32_t reserved2; /* reserved (for count or sizeof) */
uint32_t reserved3; /* reserved */
};
对于__got、__stubs、__la_symbol_ptr这几个 section,该结构体reserved1描述了对应 list 中条目在 [indirect symbol table]
() (下文会讲, 这里就把它看成一个表就好了)中的index.
还是用上面的程序做例子
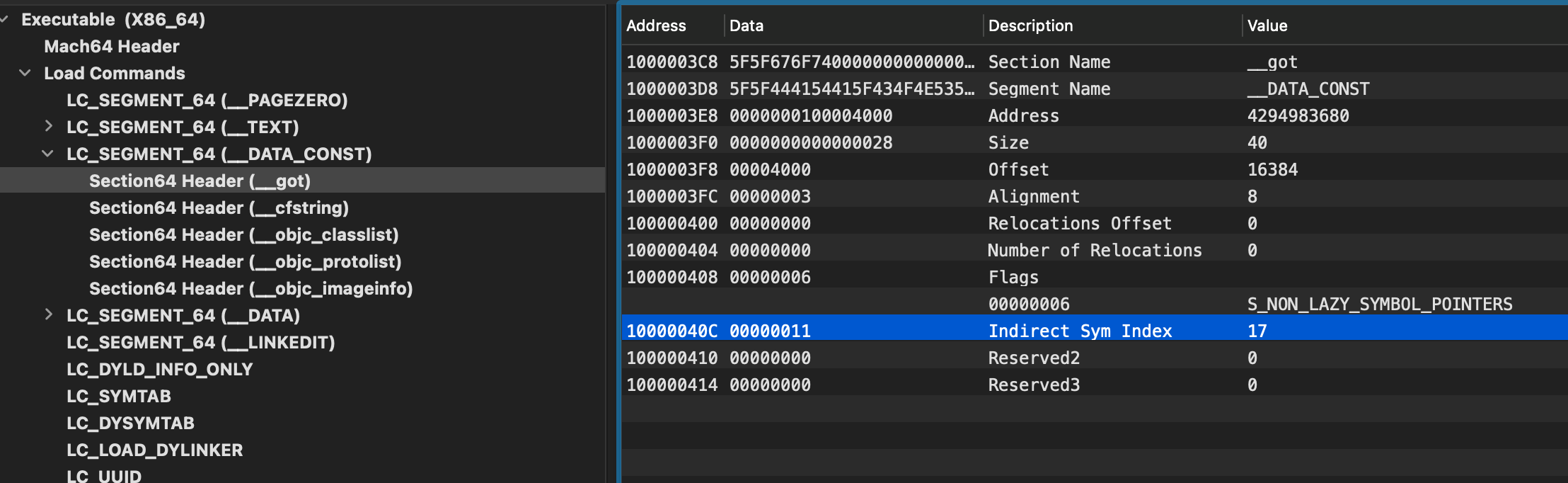 那么
那么__got符号对应indirect symbol table中第17个条目.
先告一段落, 我们重新回头来看lazy symbol的情况.
section(__TEXT,__stubs)
不同于__DATA_CONST, __got, __stubs位于__TEXT段, 所以该内容是不能运行时修改的. 该section的每个表项都是一段汇编代码, 称为符号桩. 比如上面_printf对应的项为:
0000000100002394 jmpq *0x5ce6(%rip)
# 间接寻址, 0x100002394 + 0x5ce6 = 0x100008080
section(__DATA,__la_symbol_ptr)
那么上面 0x100008080 又在哪部分呢?
$ otool -v dyld-test -s __DATA __la_symbol_ptr
dyld-test:
Contents of (__DATA,__la_symbol_ptr) section
Unknown section type (0x00000007)
0000000100008000 ac 23 00 00 01 00 00 00 4c 24 00 00 01 00 00 00
0000000100008010 06 24 00 00 01 00 00 00 10 24 00 00 01 00 00 00
0000000100008020 1a 24 00 00 01 00 00 00 24 24 00 00 01 00 00 00
0000000100008030 2e 24 00 00 01 00 00 00 38 24 00 00 01 00 00 00
0000000100008040 b6 23 00 00 01 00 00 00 c0 23 00 00 01 00 00 00
0000000100008050 ca 23 00 00 01 00 00 00 d4 23 00 00 01 00 00 00
0000000100008060 de 23 00 00 01 00 00 00 e8 23 00 00 01 00 00 00
0000000100008070 f2 23 00 00 01 00 00 00 fc 23 00 00 01 00 00 00
0000000100008080 42 24 00 00 01 00 00 00
可以看到该地址位于(__DATA,__la_symbol_ptr)中,也就是说符号桩jump的目标地址是0x100002442(小端).
section(__TEXT, __stub_helper)
继续查找该地址, 发现位于__TEXT, __stub_helper中
$ otool -v dyld-test -s __TEXT __stub_helper
dyld-test:
Contents of (__TEXT,__stub_helper) section
000000010000239c leaq 0x712d(%rip), %r11
00000001000023a3 pushq %r11
00000001000023a5 jmpq *0x1c75(%rip)
00000001000023ab nop
....
0000000100002438 pushq $0xd2
000000010000243d jmp 0x10000239c
0000000100002442 pushq $0x1ca
0000000100002447 jmp 0x10000239c
000000010000244c pushq $0x19
0000000100002451 jmp 0x10000239c
可以看到这段代码的执行流程 0000000100002442 -> ..-> 000000010000239c -> ..-> 00000001000023a5. 最终执行:
00000001000023a5 jmpq *0x1c75(%rip)
00000001000023ab nop
# 0x1c75 + 0x1000023ab = 0x100004020
继续查找0x100004020发现位于__DATA_CONST,__got中, 跟上面分析no-lazy symbol一样, 最终indirect symbol table中. 其实所有的 lazy 函数符号在dyld初始化后, 都是指向dyld_stub_binder函数.
__LINKEDIT
从OS X 10.5或10.6开始,苹果决定在Mach-O文件中实现一个特殊的段,供DYLD使用。这个段,传统上称为__LINKEDIT,由DYLD在链接和绑定符号的过程中使用的信息组成。上面提到的indirect symbol table就位于这一部分.
LC_SEGMENT定义了该segment, DYLD依靠一个特殊的加载命令LC_DYLD_INFO_ONLY来作为段的 “目录"进一步对动态loader info做了细分.
下面是用jtool输出的格式(类似pagestuff).
$ ./jtool --pages /bin/ls -arch x86_64
0x0-0x8000 __TEXT
0x3d84-0x73ce __TEXT.__text
0x73ce-0x759c __TEXT.__stubs
0x759c-0x78ae __TEXT.__stub_helper
0x78b0-0x7a93 __TEXT.__const
0x7a93-0x7f59 __TEXT.__cstring
0x7f5c-0x7ff8 __TEXT.__unwind_info
0x8000-0xc000 __DATA
0x8000-0x8008 __DATA.__nl_symbol_ptr
0x8008-0x8038 __DATA.__got
0x8038-0x82a0 __DATA.__la_symbol_ptr
0x82a0-0x84c8 __DATA.__const
0x84d0-0x84f8 __DATA.__data
0xc000-0xe890 __LINKEDIT
0xc000-0xc018 Rebase Info (opcodes)
0xc018-0xc080 Binding Info (opcodes)
0xc080-0xc5f0 Lazy Bind Info (opcodes)
0xc5f0-0xc610 Exports
0xc610-0xc658 Function Starts
0xc658-0xc680 Data In Code
0xc680-0xcbd0 Symbol Table
0xcbd0-0xce54 Indirect Symbol Table
0xce58-0xd230 String Table
0xd230-0xe890 Code Signature
__LINKEDIT的一般布局如下, DYLD大量使用了ULEB128编码(按Jonathan Levin的说法这是一种粗陋的编码方法。), 底层实现者将广泛熟悉该编码,该编码在DWARF和其他二进制相关格式中也有使用.

DYLD Opcodes
DYLD使用一种特殊的编码–由各种opcode组成–来存储和加载符号绑定信息。这些操作码用于填充LC_DYLD_INFO命令所指向的rebase信息和binding表。有两种类型的操作码。Rebasing操作码和Binding操作码。
Binding操作码(用于lazy和non-lazy符号)被定义为BIND_xxx常数:
| opcode | val | desc |
|---|
| DONE | 0x00 | 将当前记录push到导入栈, 并清零记录状态 |
| SET_DYLIB_ORDINAL_IMM | 0x10 | 设置dylib ordinal为immediate(低4-bits). 用于0-15的ordinal number |
| SET_DYLIB_ORDINAL_ULEB | 0x20 | 以 ULEB128 编码 dylib ordinal 。 用于16+的ordinal number |
| SET_DYLIB_SPECIAL_IMM | 0x30 | 设置dylib序数,以0或负数为immediate.该值为sign扩展。 目前已知的数值是: BIND_SPECIAL_DYLIB_SELF (0) BIND_SPECIAL_DYLIB_MAIN_EXECUTABLE(-1) BIND_SEPCIAL_DYLIB_FLAT_LOOKUP(-2) |
| SET_SYMBOL_TRAILING_FLAGS_IMM | 0x40 | 设置符号名(以NULL结尾的char[]) 在immediate值中的标志可以是BIND_SYMBOL_FLAGS_WEAK_IMPORT(0) 或 BIND_SYMBOL_FLAGS_NON_WEAK_DEFINITION(8) |
| SET_TYPE_IMM | 0x50 | 设置符号类型. TYPE_POINTERTYPE_TEXT_ABSOLUTE32TYPE_TEXT_PCREL32 |
| SET_ADDEND_SLEG | 0x60 | 以SLEB128编码设置addend字段 |
| SET_SEGMENT_AND_OFFSET_ULEB | 0x70 | 将Segment设置为immediate value, 地址以SLEB128编码. |
| ADD_ADDR_ULEB | 0x80 | 将address字段以SLEB128编码. |
| DO_BIND | 0x90 | 对当前表行进行绑定 |
| DO_BIND_ADD_ADDR_ULEB | 0xA0 | 进行绑定, 并以ULEB128对地址进行编码 |
| DO_BIND_ADD_ADDR_IMM_SCALED | 0xB0 | 进行绑定, 并以使用scaling添加immediate (lower 4-bits) |
| DO_BIND_ADD_ADDR_ULEB _TIMES_SKIPPING_ULEB | 0xC0 | 对多个符号进行绑定,并跳过几个字节.罕见 |
操作码填充了绑定表中行项的各个列,基本格式是:
opcode + [immediate|ULEB128整数|字符数组]
每行以DO_BIND结束。每一行默认携带前一行的值,因此只有在两个符号之间列值发生变化时才会指定一个操作码。这样就可以对表进行压缩。
举个例子🌰:
0x0000 BIND_OPCODE_SET_DYLIB_ORDINAL_IMM(3) # 设置 DYLIB to #3 (第三个LC_LOAD_DYLIB)
0x0001 BIND_OPCODE_SET_SYMBOL_TRAILING_FLAGS_IMM(0x00, __DefaultRuneLocale) # 设置符号名为 __DefaultRuneLocale
0x0016 BIND_OPCODE_SET_TYPE_IMM(1) # 设置类型为 pointer
0x0017 BIND_OPCODE_SET_SEGMENT_AND_OFFSET_ULEB(0x02, 0x00000000) # 设置segement #2 (__DATA)
0x0019 BIND_OPCODE_DO_BIND() # 第一行结束
#
# 第二行会完全继承第一行的值, 除了覆盖symbol name:
#
0x001A BIND_OPCODE_SET_SYMBOL_TRAILING_FLAGS_IMM(0x00, ___stack_chk_guard) # 设置符号名 __stack_chk_guard
0x002E BIND_OPCODE_DO_BIND()
#
# 同样的第三行也只用覆盖符号名:
0x002F BIND_OPCODE_SET_SYMBOL_TRAILING_FLAGS_IMM(0x00, ___stderrp)
0x003B BIND_OPCODE_DO_BIND()
这些操作码是由上面提到的dyld_stub_binder使用的,我们后面会讨论。但在此之前,我们必须再做一个转折来解释Mach-O中的两种类型的符号表。
Symbol Tables
在Mach-O文件中的符号表由LC_SYMTAB命令描述的。链接器是通过 LC_SYMTAB 这个 load command 找到 symbol table, LC_SYMTAB 对应的 command 结构体如下:
struct symtab_command {
uint32_t cmd; /* LC_SYMTAB */
uint32_t cmdsize; /* sizeof(struct symtab_command) */
uint32_t symoff; /* symbol table offset */
uint32_t nsyms; /* number of symbol table entries */
uint32_t stroff; /* string table offset */
uint32_t strsize; /* string table size in bytes */
};
symoff和nsyms指示了符号表的位置和条目,stroff和strsize指示了字符串表的位置和长度.
每个 symbol entry 长度是固定的,其结构由内核定义:
struct nlist_64 {
union {
uint32_t n_strx; /* index into the string table */
} n_un;
uint8_t n_type; /* type flag, see below */
uint8_t n_sect; /* section number or NO_SECT */
uint16_t n_desc; /* see <mach-o/stab.h> */
uint64_t n_value; /* value of this symbol (or stab offset) */
};
n_un: 符号的名字(在一个 Mach-O 文件里,具有唯一性)n_sect: 符号所在的 section index(内部符号有效值从 1 开始,最大为 255)n_value: 符号的地址值(在链接过程中,会随着其 section 发生变化)
Indirect Symbol Table
indirect symbol table 由LC_DYSYMTAB定义,后者的参数类型是一个dysymtab_command结构体:
struct dysymtab_command {
uint32_t cmd; /* LC_DYSYMTAB */
uint32_t cmdsize; /* sizeof(struct dysymtab_command) */
uint32_t ilocalsym; /* index to local symbols */
uint32_t nlocalsym; /* number of local symbols */
uint32_t iextdefsym;/* index to externally defined symbols */
uint32_t nextdefsym;/* number of externally defined symbols */
uint32_t iundefsym; /* index to undefined symbols */
uint32_t nundefsym; /* number of undefined symbols */
uint32_t tocoff; /* file offset to table of contents */
uint32_t ntoc; /* number of entries in table of contents */
uint32_t modtaboff; /* file offset to module table */
uint32_t nmodtab; /* number of module table entries */
uint32_t extrefsymoff; /* offset to referenced symbol table */
uint32_t nextrefsyms; /* number of referenced symbol table entries */
uint32_t indirectsymoff; /* file offset to the indirect symbol table */
uint32_t nindirectsyms; /* number of indirect symbol table entries */
uint32_t extreloff; /* offset to external relocation entries */
uint32_t nextrel; /* number of external relocation entries */
uint32_t locreloff; /* offset to local relocation entries */
uint32_t nlocrel; /* number of local relocation entries */
};
本质上,indirect符号表是 index 数组,即每个条目的内容是一个 index 值,indirectsymoff和nindirectsyms这两个字段定义了 indirect symbol table 的位置信息,每一个条目是一个 4 bytes 的 index 值.
dyld_stub_binder
至此我们就可以通过indirect符号表找到符号表中的符号了. 但是 lazy binding 最终调用的是dyld_stub_binder, 这个函数具体做了什么呢?
dyld_stub_binder:
stp fp, lr, [sp, #-16]!
mov fp, sp
sub sp, sp, #240
stp x0,x1, [fp, #-16] ; x0-x7 are int parameter registers
stp x2,x3, [fp, #-32]
stp x4,x5, [fp, #-48]
stp x6,x7, [fp, #-64]
stp x8,x9, [fp, #-80] ; x8 is used for struct returns
stp q0,q1, [fp, #-128] ; q0-q7 are vector/fp parameter registers
stp q2,q3, [fp, #-160]
stp q4,q5, [fp, #-192]
stp q6,q7, [fp, #-224]
ldr x0, [fp, #24] ; move address ImageLoader cache to 1st parameter
ldr x1, [fp, #16] ; move lazy info offset 2nd parameter
; call dyld::fastBindLazySymbol(loadercache, lazyinfo)
bl __Z21_dyld_fast_stub_entryPvl
mov x16,x0 ; save target function address in lr
; restore parameter registers
ldp x0,x1, [fp, #-16]
ldp x2,x3, [fp, #-32]
ldp x4,x5, [fp, #-48]
ldp x6,x7, [fp, #-64]
ldp x8,x9, [fp, #-80]
ldp q0,q1, [fp, #-128]
ldp q2,q3, [fp, #-160]
ldp q4,q5, [fp, #-192]
ldp q6,q7, [fp, #-224]
mov sp, fp
ldp fp, lr, [sp], #16
add sp, sp, #16 ; remove meta-parameters
可以看到最终通过调用dyld::fastBindLazySymbol, 该函数内部通过ImageLoaderMachO::getLazyBindingInfo根据opcode找到符号的真实地址, 并将该地址写入__la_symbol_ptr条目, 最后跳转符号地址.
总结
如图

参考
ld64
![]()
本文基于ld版本
> @(#)PROGRAM:ld PROJECT:ld64-609
> BUILD 07:59:13 Aug 25 2020
> configured to support archs: armv6 armv7 armv7s arm64 arm64e arm64_32 i386 x86_64 x86_64h armv6m armv7k armv7m armv7em LTO support using: LLVM version 12.0.0, (clang-1200.0.32.2) (static support for 27, runtime is 27) TAPI support using: Apple TAPI version 12.0.0 (tapi-1200.0.23)
简介
ld files... [options] [-o outputfile]
描述
ld命令将多个对象文件和库结合起来,解析引用,并产生一个输出文件。ld可以产生一个最终的链接镜像(可执行文件、dylib或bundle),或者使用-r选项,产生一个 另一个object file。 如果不使用-o选项,产生的输出文件被命名为 “a.out”。
通用
链接器接受通用(多架构)输入文件,但总是创建一个 “thin”(单架构)的标准Mach-O输出文件。 输出文件的体系结构是通过使用 -arch 选项确定的。 如果不使用这个选项,ld会尝试通过按命令行顺序检查对象文件来确定输出架构。 第一个 “thin"架构决定了输出的文件。 如果没有输入对象文件是 “thin"文件,则使用主机的原生32位架构。
通常情况下,不会直接使用ld。 而是由编译器驱动程序调用ld。编译器驱动程序可以传递多个-arch选项,它将通过多次调用ld来创建一个通用的最终链接镜像。然后运行 lipo 将输出合并到一个通用文件中.
布局
object file按照命令行中指定的顺序加载。 segment和这些segment中的section将按照它们在被链接的 object file 中遇到的顺序出现在输出文件中。 所有零填充的section将出现在其segment中所有非零填充的section之后。 用 -sectcreate 选项从文件中创建的section将排在 .o 文件的section之后。使用-order_file选项将改变上面的布局规则,并将指定的符号移动到其部分的开头。
库
静态库(又名静态归档)是一个.o文件的集合,它的目录表列出了.o文件中的全局符号,只有在需要解决某些符号引用的时候,ld才会从静态库中提取.o文件。 与传统的链接器不同,ld会在链接的同时不断搜索静态库。不需要在命令行中多次指定静态库。
动态库(又名dylib或框架)是一个最终的链接镜像。 在命令行上放一个动态库会导致两件事。1) 生成的最终链接镜像将有编码表明它依赖于该动态库。2)从动态库导出的符号用于解析引用。
动态库和静态库都是按照它们在命令行中出现的样子进行搜索的
搜索路径
ld维护一个目录列表,用来搜索要使用的库或框架。 默认的库搜索路径是/usr/lib,然后是/usr/local/lib。 ld选项将添加一个新的库搜索路径。 默认的框架搜索路径是/Library/Frameworks,然后是/System/Library/Frameworks。 (注意:以前,/Network/Library/Frameworks是在默认路径的最后面。 如果你需要这个功能,你需要明确添加-F/Network/Library/Frameworks)。) -F选项将添加一个新的框架搜索路径。 -Z选项将删除标准搜索路径。 -syslibroot选项将为所有搜索路径添加一个前缀。
二级命名空间(Two-level namespace)
默认情况下,所有解析到动态库的引用都会记录它们被解析到的库。在运行时,dyld 使用这些信息直接解析符号。 另一种方法是使用 -flat_namespace 选项。 使用-flat_namespace则不记录库。 在运行时,dyld 将在解析符号时按加载顺序搜索每个动态库。这虽然速度较慢,但更像其他操作系统解析符号的方式.
间接动态库
如果命令行指定要与 dylib A 链接,而当 dylib A 被构建时,它与 dylib B 链接,那么 B 被认为是间接的 dylib。 当链接到两级命名空间时,ld并不查看间接的dylibs,除非是直接的dylibs再导出。 另一方面,当为扁平命名空间链接时,ld会加载所有间接dylibs,并使用它们来解析引用。 尽管间接dylibs是通过完整路径指定的,ld首先使用指定的搜索路径来定位每个间接dylib。 如果使用搜索路径无法找到,则使用完整路径。
动态库未定义
当链接到二级命名空间时,ld并不验证dylibs中的undefines是否真的存在。 但是当为扁平命名空间链接时,ld会检查所有加载的dylibs中的undefines是否有一个匹配的定义,有时用于强制从静态库中加载所选函数。
OPTIONS
控制输出类型
-lx: 这个选项告诉链接器在库搜索路径中搜索 libx.dylib 或 libx.a。 如果字符串x是y.o的形式,那么这个文件会在同样的地方被搜索,但不会在文件名前加上 “lib “或附加”.a “或”.dylib”。-needed-lx: 这与 -lx 相同,但意思是即使没有使用 dylib 的符号,也要与 dylib 进行真正的链接,因此,它可以用来消除未使用 dylib 的警告。-reexport-lx: 这与-lx相同,但指定库x中的所有符号应该可以被链接到正在创建的库的clients使用。 这在以前是通过一个单独的-sub_library选项完成的。-upward-lx: 这与 -lx 相同,但指定 dylib 是向上的依赖关系。-hidden-lx: 这与定位静态库的-lx相同,但将静态库中的所有全局符号视为可见性隐藏。 用于构建静态库,但不想从该静态库中导出任何东西。-weak-lx: 这与 -lx 相同,但会强制将库和对它的所有引用标记为弱导入。 也就是说,允许库在运行时缺失。-needed_library path_to_dylib: 这与将 path_to_dylib 放在链接行上是一样的,区别是即使没有使用 dylib 的符号,也要真正与 dylib 链接。 因此,它可以用来消除未使用的dylib的警告。-reexport_library path_to_library:指定库路径中的所有符号都应该被链接到正在创建的库的clients所使用. 这在以前是通过一个单独的-sub_library选项来实现的.-upward_library path_to_library: 将dylib标记为向上的依赖关系-weak_library path_to_library: 这和在链接行中列出一个库的文件名路径是一样的,只是它强制将库和所有对它的引用标记为弱导入.-Ldir: 在搜索库的目录列表中添加dir。 用-L指定的目录将按照它们在命令行中出现的顺序,在默认的搜索路径之前进行搜索。在Xcode4及以后的版本,-L和目录之间可以有一个空格。-Z: 当搜索库和框架时,不要搜索标准目录.-syslibroot rootdir: 在搜索库或框架时,将rootdir预置到所有搜索路径中。-search_paths_first: 这现在是默认的(在Xcode4工具中)。 当处理-lx时,链接器现在会在其库搜索路径中搜索每个目录中的 “libx.dylib”,然后搜索 “libx.a”,然后再进入库搜索路径的下一个路径.-search_dylibs_first: 默认情况下,当处理-lx时,链接器会在库搜索路径中的每个目录中搜索 “libx.dylib”,然后搜索 “libx.a”。 这个选项改变了行为,首先在库所有搜索路径的每个目录中搜索’libx.dylib’形式的文件,然后在库搜索路径中搜索’libx.a’形式的文件。-framework name[,suffix]: 这个选项告诉链接器搜索’name.framework/name’的框架搜索路径。 如果指定了可选的后缀,框架将首先搜索带有后缀的名称,然后再搜索不带后缀的(比如先找’name.framework/name_suffix',如果没有的话就找’name.framework/name')-weak_framework name[,suffix]: 这与-framework name[,suffix]相同,但会强制将框架和所有对它的引用标记为弱导入。 注意:由于clang的优化,如果函数没有被标记为weak,如果函数地址为NULL,编译器不做任何检查。-reexport_framework name[,suffix]: 指定了该框架中的所有符号都应该提供给链接到正在创建的库的clients。 这在以前是用单独的-sub_umbrella选项完成.-upward_framework name[,suffix]: 指定了该框架是向上的依赖关系.-Fdir: 在搜索框架的目录列表中添加dir。 用-F指定的目录会按照它们在命令行中出现的顺序,在默认搜索路径之前进行搜索。在Xcode4及以后的版本,在-F和dir之间可以有一个空格.-all_load: 加载静态归档库的所有成员-ObjC: 加载实现 Objective-C 类或类别的静态归档库的所有成员-force_load path_to_archive: 加载指定静态归档库的所有成员。 注意:-all_load 强制加载所有归档库的所有成员。 这个选项允许你针对一个特定的存档.-load_hidden path_to_archive: 像往常一样使用指定的静态库,但将静态库中的所有全局符号视为可见性隐藏。 当构建一个使用静态库的动态库时很有用。
其他
-sectcreate segname sectname file: segname中的sectname是根据file的内容创建的。segname和sectname的组合必须是唯一的,不能和一个来自任何其他输入的段(segname,sectname)的组合重复.-filelist file[,dirname]: 指定链接器应该链接的文件。 这是在命令行中列出文件的另一种方式。 文件名每行只列出一个,用换行符隔开(空格和制表符被认为是文件名的一部分).如果指定了可选的目录名dirname,则会在列表文件中的每个文件名前加上它。-dtrace file: 在生成最终链接镜像时启用 dtrace 静态探针。 文件必须是声明静态探针的 DTrace 脚本.
优化相关选项
-dead_strip: 删除入口点或导出符号无法到达的函数和数据
-order_file file: 改变函数和数据的排列顺序。 对于输出文件中的每个section, 该section中在顺序文件中指定的任何符号都会被移到该section的开头.并以与顺序文件中相同的顺序排列. 顺序文件是文本文件,每行有一个符号名。 以#开头的行是注释。 符号名前面可以选择使用它的对象文件叶名和冒号(例如foo.o:_foo)。 这对于在多个文件中出现的静态函数/数据是很有用的。 符号名也可以选择在前面加上架构(例如ppc:_foo或ppc:foo.o:_foo)。 这使得您可以使用一个适用于多种架构的命令文件。 c-字符串可以通过在命令文件中引用字符串来排序(例如 “Hello, world\n”)。
-no_order_inits: 当不使用-order_file选项时,链接器会按照对象文件的顺序排列函数,并且会将所有初始化例程移到__text部分的开头,而将终止符例程移到最后。使用该选项可以禁用初始化器和终止器的自动重排。
-no_order_data: 默认情况下,链接器会对__DATA段中全局数据进行重新排序,这样dyld在启动时需要调整的所有全局变量都会在__DATA段的前部。 这减少了启动时脏页面的数量。 此选项将禁用该优化.
-platform_version platform min_version sdk_version: 该设置用于指示平台、输出支持该平台上使用的最低的支持版本,以及输出所依据的SDK版本。platform是一个在<mach-o/loader.h>中定义的数值,也可以是以下字符串之一:
- macos
- ios
- tvos
- watchos
- bridgeos
- mac-catalyst
- ios-simulator
- tvos-simulator
- watchos-simulator
- driverkit
指定一个较新的min或SDK版本,可以使链接器在输出文件中承担该操作系统或SDK的功能。min_version和sdk_version的格式是一个版本号,如10.13或10.14. 相似的还有-macos_version_min version和-ios_version_min选项.
-image_base address: 指定 dylib 或 bundle 的首选加载地址。参数地址是一个十六进制数字,可选择前导符0x。 通过为程序加载的所有 dylibs 和 bundle 选择非重叠的地址,可以缩短启动时间,因为 dyld 不需要 “rebase “映像(即调整映像中的指针以在加载的地址工作)。 通常情况下,不使用这个选项更容易,而是使用 rebase(1) 工具,并给它一个 dylibs 列表。 然后,它将为列表选择非重叠的地址,并将它们全部rebase。 这个选项也被称为 -seg1addr,以保证兼容性。
-no_implicit_dylibs: 在创建两级命名空间最终链接映像时,通常链接器会把隐性链接的公共dylibs吊起来,使两级命名空间编码对dyld来说更有效率。例如,Cocoa重导出AppKit,AppKit重导出Foundation。 如果你用-framework Cocoa链接并使用Foundation的符号,链接器将隐式地添加一个加载命令来加载Foundation,并将该符号编码为来自Foundation。 如果您使用这个选项,链接器将不会为Foundation添加加载命令,并将符号编码为来自Cocoa的符号。 那么在运行时,dyld将不得不在Foundation中搜索Cocoa和AppKit,然后再找到符号。
-exported_symbols_order file:当以Mac OS X 10.6或更高版本为目标时,可以优化导出的符号信息的格式,使常用符号的查找速度更快。 此选项用于传递一个包含正在构建的动态库的客户端最常使用的符号列表的文件。并非所有导出的符号都需要列出。
-no_zero_fill_sections: 默认情况下,链接器会将所有零填充部分移动到__DATA段的末尾,并将它们配置为不使用磁盘空间。 这个选项抑制了这种优化,所以在最终的链接映像中,零填充的数据会占据了磁盘上的空间。
-merge_zero_fill_sections: 将__DATA段的所有零填充部分合并成一个__零填充section.
dylib相关
-install_name name: 在动态库中设置一个内部的 “安装路径”(LC_ID_DYLIB)。任何链接到该库的客户端都会将该路径记录为dyld应该定位该库的方式。 如果没有指定这个选项,那么将使用-o路径。 这个选项也被称为-dylib_install_name,以保证兼容性。-mark_dead_strippable_dylib: 指定正在构建的dylib可以被任何客户端dead strip。 也就是说,dylib没有初始化的副作用。 因此,如果一个客户端链接到dylib,但从未使用任何来自它,链接器可以优化掉dylib的使用。-compatibility_version number: 指定库的兼容性版本号。 当dyld加载库时,会检查兼容性版本,如果程序的版本大于库的版本,则为错误。 号码格式为X[.Y[.Z]],其中X必须是小于或等于65535的非零正数,.Y和.Z是可选的,如果存在必须是小于或等于255的非负数。 如果没有指定兼容性版本号,它的值为0,并且在使用库时不进行检查。 这个选项也叫-dylib_compatibility_version,用于兼容性。-current_version number: 指定库的当前版本号。库的用户可以通过编程获得库的当前版本,这样就可以准确地确定自己使用的是哪个版本的库。 编号的格式为X[.Y[.Z]],其中X必须是小于或等于65535的非零正数,.Y和.Z是可选的,如果存在必须是小于或等于255的非负数。 如果没有指定版本号,那么它的值为0,这个选项也被称为-dylib_current_version,以保证兼容性。
可执行文件时的选项
-pie: 创建位置无关(PIE)的可执行文件.在Mac OS X 10.5及以后的版本中,操作系统在每次执行时都会在随机地址加载一个PIE。你不能从使用-mdy-namic-no-pic编译的.o文件中创建一个PIE。 这意味着代码生成不那么理想,但地址随机化增加了一些安全性。当以Mac OS X 10.7或更高版本为目标时,PIE是主可执行文件的默认值。-no_pie: 不使用PIE技术构建可执行文件. 在10.6或更早的版本上默认-pagezero_size size: 默认情况下,链接器从地址0开始创建一个不可读的段,名为__PAGEZERO。 如果一个NULL指针被取消引用,它的存在将导致一个总线错误。 参数大小是一个十六进制数,前面有一个可选的0x。 如果size为0,链接器将不会生成一个零页段。 在32位架构上,默认情况下,零页大小为4KB。 在64位架构上,默认大小为4GB。-stack_size size: 指定程序中主线程的最大堆栈大小。 如果没有这个选项,一个程序有8MB的堆栈。 参数大小是一个十六进制数,可选择前导0x。大小应该是架构的页大小(4KB或16KB)的倍数。-allow_stack_execute: 标记可执行文件,使任务中的所有堆栈都有堆栈执行权限。这包括pthread堆栈。-export_dynamic: 在LTO期间保留main可执行文件中的所有全局符号。如果没有这个选项,链接时间优化允许内联和删除全局函数。当main可执行文件可能会加载一个需要main可执行文件中某些符号的插件时,就会使用这个选项。
bundle相关
-bundle_loader executable:这指定了将executable加载到被链接的 bundle 输出文件中。 从指定的可执行文件中检查来自 bundle 的未定义符号,就像它是与 bundle 链接的动态库一样。
Object file
-keep_private_externs: 不要把私有外部(也就是 visibility=hidden)符号变成静态符号,而是在生成的Object file中把它们作为私有外部。-d: 强行对常用符号进行定义。 即把暂定的definitions变成real definitions。
符号解析相关
-[un]exported_symbols_list filename: 指定的文件名包含一个全局符号名称的列表,它将作为全局符号留在输出文件中。 所有其它的全局符号将被视为被标记为__private_extern__ (也就是可见性=hidden),并且在输出文件中不会成为全局符号。file-name 中列出的符号名称必须每行一个。 前导和尾部的空格不属于符号名的一部分。 以#开头的行会被忽略,只有空格的行也会被忽略。 支持一些通配符(类似于shell文件匹配)。 通配符 * 匹配零个或多个字符。 ? 匹配一个字符。 [abc] 匹配一个字符,该字符必须是’a'、‘b’或’c’。 [a-z] 匹配从’a’到’z’的任何一个小写字母。-unexported_symbols_list则刚好相反.-[un]exported_symbol symbol: 指定的符号将被添加到全局符号名称列表中,这些符号将作为全局符号保留在输出文件中。 对于短列表,这比创建一个文件并使用-exported_symbols_list更方便。-reexported_symbols_list file: 重新导出依赖的dylib中实现的符号名称列表.-alias symbol_name alternate_symbol_name: 为符号创建一个别名。 默认情况下,别名符号具有全局可见性。 这个选项的前身是-idef:indir选项-alias_list filename: 指定的文件名包含一个别名列表。符号名和它的别名在一行,用空格隔开。以#开头的行将被忽略。-flat_namespace: 改变符号在构建时和运行时的解析方式。使用-two_levelnamespace(默认)时,链接器只搜索命令行上的dylibs的符号,并记录它们在哪个dylibs中被找到。 使用-flat_namespace时,链接器会搜索命令行上的所有dylibs以及这些原始dylibs所依赖的所有dylibs。 链接器不会记录外部符号来自哪个 dylib,所以在运行时 dyld 会再次搜索所有的image并使用它找到的第一个定义。 此外,加载的 flat_namespace dylibs 中的任何未定义都必须在构建时进行解析。-u symbol_name: 指定必须定义符号symbol_name才能成功链接。 这对于强制从静态库中加载选定的函数很有用。-U symbol_name: 指定 symbol_name 可以没有定义。 使用-two_levelnamespace时,产生的符号将被标记为dynamic_lookup,这意味着dyld将搜索所有加载的image.-undefined treatment: 指定如何处理未定义的符号,选项有:error, warning, suppress, 或 dynamic_lookup。选项有:error, warning, suppress, 或 dynamic_lookup。 默认为error.-rpath path: 将路径添加到正在创建的image的runpath搜索路径列表中。 在运行时,dyld会使用runpath来搜索加载路径以@rpath/开头的dylibs。-commons treatment: 指定如何解决与dylibs相关的共通点(也就是暂定定义)。 选项有:ignore_dylibs, use_dylibs, error。 默认值是ignore_dylibs,这意味着链接器将把object file中的暂定定义变成真正的定义,甚至不检查dylibs的冲突。 dylibs 选项意味着链接器应该检查链接的 dylibs 的定义,并使用它们来替换对象文件中的暂定定义。 错误选项意味着每当对象文件中的暂定定义与链接的dylib中的外部符号发生冲突时,链接器就应该发出一个错误。 也请参见 -warn_commons。
连接器内省选项
-why_load: 记录静态库中的每个对象文件为什么被加载。也就是需要什么符号。 出于兼容性考虑,也叫-whyload-why_live symbol_name: 记录对 symbol_name 的一系列引用。 仅适用于 -dead_strip 。 它可以帮助调试为什么你认为应该被删除的dead strip却没有被删除。 关于语法和通配符的使用,请参见 -exported_symbols_list。-print_statistics: 记录链接器使用的内存量和时间信息.-t: 记录链接器加载的每一个文件(对象、存档或dylib)。 用于调试搜索路径中加载错误库的问题。-whatsloaded: 只记录链接器加载的object files.-order_file_statistics: 记录-order_file的处理信息-map map_file_path: 将一个map文件写入指定的路径,该文件详细说明了输出image中的所有符号及其地址。
符号表优化的选项
-S: 不要将调试信息(STABS或DWARF)放在输出文件中-x: 不要在输出文件的符号表中放入非全局符号。非全局符号(non-global symbol)在调试和获取回溯轨迹中的符号名时很有用,但在运行时不会使用。如果-x与-r一起使用,非全局符号名就不会被删除,而是用一个唯一的虚名代替,这个虚名将在链接到最终的链接image中时被自动删除。 这使得使用符号来分解代码和数据的dead code striping能够正常工作,并保证了删除源符号名的安全性.-non_global_symbols_strip_list filename: 指定的文件名包含一个非全局符号名的列表,这些符号名应该从输出文件的符号表中删除。 所有其他的非全局符号名将保留在输出文件的符号表中。关于语法和通配符的使用,请参见-exported_symbols_list。-non_global_symbols_no_strip_list filename: 指定的文件名包含一个非全局性的符号名列表,这些符号名应该保留在输出文件的符号表中。 所有其他的符号名将从输出文件的符号表中删除。关于语法和通配符的使用,请参见-exported_symbols_list。-oso_prefix prefix-path: 当生成调试图时,链接器将从OSO符号的路径中删除指定的前缀-路径。这可以用来帮助构建服务器生成相同的二进制文件
Bitcode 构建相关
-bitcode_bundle: 在输出二进制文件中生成一个嵌入的bitcode bundle。bitcode bundle嵌入在section(__LLVM,__bundle)部分。 这个选项要求所有的对象文件、静态库和用户框架/dylibs都包含bitcode。 注意:并不是所有的链接器选项都支持和-bitcode_bundle一起使用。-bitcode_hide_symbols: 与-bitcode_bundle一起指定这个选项,可以从输出的bitcode bundle中隐藏所有未导出的符号。 隐藏符号的过程可能是不可逆的。要获得一个反向映射文件来恢复所有的符号,使用-bitcode_symbol_map选项-bitcode_symbol_map path: 输出bitcode符号反向映射文件(.bcsymbolmap)。如果路径是一个现有的目录,UUID.bcsymbolmap将被写入该目录。 否则,反转映射将被写入path指定的文件.
比较少用的选项
@response_file_path: 将response_file_path处的文件内容插入到参数中。这允许linker命令行参数存储在一个文件中。 注意: ld通常是通过clang调用的,clang也会在命令行解释@file。 要想让 clang 忽略 @file 并将其传递给 ld,使用 -Wl,@file.-v: 打印linker版本-version_detail: 以JSON格式打印链接器的版本信息.-no_weak_imports: 如果任何符号是weak import的(即允许在运行时未解析(NULL)),则出现错误。对基于配置的项目很有用,因为这些项目假设是在同一个操作系统版本上构建和运行的。-no_deduplicate: 不要在链接器中运行重复数据删除pass-verbose_deduplicate: 打印通过删除重复数据(deduplication)去掉的函数名称和节省的总代码量.-no_inits: 如果输出包含任何静态initializers, 则出错-no_warn_inits: 如果输出包含任何静态initializers, 也不报警告-debug_variant: 忽略二进制输送给customer的错误警告-unaligned_pointers treatment: 指定如何处理__DATA段中未对齐的指针.选项有:‘warning’、‘error’或’suppress’。‘warning’, ‘error’, 或 ‘suppress’. arm64e的默认值是’error',而所有其他架构的默认值是’suppress'-dirty_data_list filename: 指定一个包含可能被污染的数据符号名称的文件。 如果链接器有创建一个__DATA_DIRTY段,那么这些符号将被移到该段中.-max_default_common_align value: 任何没有显式对齐的普通符号(也就是暂定的,或者未初始化(归零)的变量)通常都会被对齐到它们的下一个2的幂数大小(例如,一个240字节的数组是256个对齐). 这个选项可以让你减少最大对齐度。 例如,值为0x40将减少240字节数组的对齐方式为64字节(而不是256)。如果不使用 -max_default_common_align,对于 -preload,默认对齐方式已经被限制为 0x8 (2^3) 字节,对于所有其他输出类型,默认对齐方式为 0x8000 (2^15)。-move_to_rw_segment segment_name filename: 将数据符号移动到另一个段。 命令行选项指定目标段名称和包含要移动的符号列表的文件路径。 可以通过以#开头的行向符号文件添加注释。 如果一个符号名有多个实例(例如在多个文件中的 “static int foo=5;"),符号列表文件中的符号名可以用对象文件名作为前缀(例如 “init.o:_foo”)来移动一个特定的实例。-move_to_ro_segment segment_name filename: 同上, 不过该选项针对只读目标段.-rename_section orgSegment orgSection newSegment newSection: 重命名section名称-rename_segment orgSegment newSegment: 重命名segment名称-trace_symbol_layout: 用于调试 -rename_section, -rename_segment, -move_to_ro_segment, 和 -move_to_rw_segment。 这个选项可以打印出一行显示每个符号被移动的位置和原因。 注意:这些选项是连锁的。 对于每个符号,链接器首先检查-move_to_ro_segment和-move_to_rw_segment。接下来应用任何-rename_section选项,最后应用-rename_segment选项。-section_order segname colon_separated_section_list: 仅与 -preload 一起使用。 指定指定segment中section的排列顺序. 如: -section_order __ROM __text:__const:__cstring.-segment_order colon_separated_segment_list: 仅与-preload一起使用。 指定segment的排列顺序。 例如 -segment_order __ROM:__ROM2:__RAM-allow_heap_execute: 通常 i386 主可执行文件会被标记为只允许 Mac OS X 10.7 及更高版本的内核执行特定 x-bit 页的指令。这个选项覆盖了这一行为,允许执行任何页上的指令-application_extension: 指定代码被链接到应用程序扩展中使用。 链接器将验证任何被链接的动态库是否可以安全地用于应用扩展-no_application_extension: 指定被链接的代码在应用扩展中使用不安全。 例如,可以在创建一个不应该在应用程序扩展中使用的框架时使用.-fatal_warnings: 如果产生任何警告,会导致链接器以一个非零值退出-no_eh_labels: 通常在-r模式下,链接器会在__eh_framesection的所有FDE上产生.eh标签。 这个选项会抑制这些标签。 Mac OS X 10.6后链接器不需要这些标签,但早期的链接器工具需要这些标签。-warn_compact_unwind: 当生成最终的链接镜像时,链接器会处理__eh_frame section,并产生一个__unwind_info section.在 __eh_frame 中的大多数 FDE 条目可以用 __unwind_info 部分的一个 32 位值来表示。 该选项会对任何FDE不能用紧凑的unwind格式(compact unwind format)表示的函数发出警告.-warn_weak_exports: 如果最终链接的image包含弱外部符号(weak external symbol), 则发出警告.需要dyld在启动时做额外的工作来凝聚(coalesce)这些符号.-no_weak_exports: 如果最终链接的image包含弱外部符号(weak external symbol), 则报错.-objc_gc_compaction: 在最终链接的镜像中标记Objective-C镜像信息,并注明代码是为了压缩垃圾收集而构建的位。-objc_gc: 验证所有代码是否是由 -fobjc-gc 或 -fobjc-gc-only 编译所得.-objc_gc_only: 验证所有代码是否是由 -fobjc-gc-only 编译所得.-warn_unused_dylibs: 对没有使用任何符号链接的dylibs给出警告信息.-no_warn_unused_dylibs: 没有使用任何符号链接的dylibs也不给警告信息.-dead_strip_dylibs: 删除入口点或导出符号无法到达的dylibs。也就是抑制在链接过程中没有提供符号的dylibs生成加载命令指令。当链接到一个由于某种间接原因而在运行时需要的dylib时,如该dylib有一个重要的初始化器时,不应使用该选项。-allow_sub_type_mismatches: 通常链接器认为ARM的不同cpu-subtype(例如armv4t和armv6)是不同的架构,在构建时不能混合。 这个选项放宽了这个要求,允许你混合为不同的ARM子类型编译的object file.-no_uuid: 不要在输出文件中生成LC_UUID加载命令。 请注意,没有UUID的二进制文件可能导致调试器和崩溃报告工具无法跟踪和检查二进制文件。-random_uuid: 在输出文件中随机生成一个LC_UUID加载命令。默认情况下,链接器会根据输出文件内容的哈希值来生成输出文件的UUID。但是对于非常大的输出文件,哈希会减慢链接的速度。使用基于哈希值的UUID对于可重现的构建是很重要的,但如果你只是在做快速调试构建,使用-random_uuid可能会改善周转时间.-root_safe: 设置输出文件mach头中的MH_ROOT_SAFE位.-setuid_safe: 设置输出文件mach头中的 MH_SETUID_SAFE 位.-interposable: 创建动态库时,可间接访问所有导出的符号.-init symbol_name: 指定的 symbol_name 将作为第一个初始化器运行。 仅在创建动态库时使用.-sub_library library_name: 导出指定动态库. 比如/usr/lib/libobjc_profile.A.dylib的library_name为libobjc. 仅在创建动态库时使用.-sub_umbrella framework_name: 导出指定framework仅在创建动态库时使用.-allowable_client name: 限制哪些client可以链接到正在创建的动态库。 默认情况下,任何代码都可以链接到任何 dylib。但是如果一个 dylib 被认为是一小部分client的私有库,你可以用-allowable_client限定每个可以使用该动态库的client。 如果一个client是 libfoo.1.dylib,它的 -allowable_client 名称将是 “foo”。 如果客户端是Foo.framework,它的-allowable_client名称将是 “Foo”。 对于你不想让任何人链接到一个dylib的情况,你可以将-allowable_client设置为”!"。-client_name name: 启用一个bundle去链接一个通过-allowable_client创建的dylib. name 必须是创建dylib时-allowable_client指定中的一个.-umbrella framework_name: 指定动态库通过指定的umbrella framework重新导出.-headerpad size: 指定将来扩展加载命令的最小空间. 只有在后面运行 install_name_tool 来修改加载命令时才有用. 大小是一个十六进制数-headerpad_max_install_names: 自动为将来的加载命令添加空间,使所有路径都能扩展到MAXPATHLEN。 只有当你打算运行 install_name_tool 来改变加载命令时才有用.-bind_at_load: 在生成的二进制文件的mach头中设置一个位,告诉dyld在加载二进制文件时绑定所有符号,而不是懒绑定.-force_flat_namespace: 在生成的二进制文件的mach头中设置一个位,它告诉dyld不仅要为二进制文件使用flat namespace,而且要强制在进程中加载的所有dylibs和bundles上绑定flat namespace。 只能在链接主可执行文件时使用。-sectalign segname sectname value: 将其对齐方式设置为value,其中value是一个十六进制数,必须是2的整数倍.-stack_addr address: 指定栈指针值的初始地址,其中value是一个十六进制数,四舍五入到页边界.-segprot segname max_prot init_prot: 指定segname的segemnt的最大和初始化内存保护, max_prot和init_prot的值是 “r”(读)、“w”(写)、“x”(执行)和”-"(无访问)等字符的任意组合.-seg_addr_table filename: 指定一个包含动态库基址的文件。 文件的每一行都是一个十六进制的基地址,后面是空格,然后是相应dylib的安装名称。#字符表示注释.-seg_addr_table filename: 指定一个包含动态库基址的文件。 文件的每一行都是一个十六进制的基地址,后面是空格,然后是相应dylib的安装名称。#字符表示注释。-segs_read_write_addr address: 允许构建只读和读写段不连续的动态库。 指定的地址是一个十六进制数,表示读写段的基本地址。-segs_read_only_addr address: 允许构建只读和读写段不连续的动态库。 指定的地址是一个十六进制数,表示只读段的基本地址。-segaddr name address: 指定命名为name的段的起始地址。地址必须是一个十六进制数,是 4K 页大小的倍数.-seg_page_size name size: 指定segment使用的page size.默认情况下,所有segment页面大小为4096。 链接器布局segment的大小总是其页面大小的偶数倍.-dylib_file install_name:file_name: 指定动态共享库的位置与标准位置不同。install_name 指定了库通常所在的路径,file_name 指定了你想使用的库的路径,例如,如果你链接到一个依赖动态库libsys的库,而你的libsys安装在非默认位置,那么使用这个选项。 例如,如果您链接到一个依赖于动态库 libsys 的库,并且您将 libsys 安装在一个非默认位置,您可以使用这个选项: -dylib_file /lib/lib-sys_s.A.dylib:/me/lib/libsys_s.A.dylib。-prebind: 所创建的输出文件将是预绑定格式。 在Mac OS X 10.3和更早的版本中使用的,以提高启动性能。-weak_reference_mismatches treatment: 指定如果一个符号在一个object file中被弱导入,但在另一个对象文件中没有被弱导入,该如何处理。 有效的处理方法是:错误、弱或非弱导入。 默认值是non-weak。-read_only_relocs treatment: 允许使用重定位,这将导致dyld修改(写后复制)只读页面。 编译器通常不会产生这样的代码.-force_cpusubtype_ALL: 只适用于 -arch ppc。 它告诉链接器忽略object file中编码的PowerPC cpu要求(如G3, G4或G5),并将生成的二进制文件标记为可在任何PowerPC cpu上运行。-dylinker_install_name path: 只用于构建dyld-no_arch_warnings: 忽略关于-arch标志有错误架构的文件的警告信息.-arch_errors_fatal: 将-arch标志有错误架构的文件的警告转化为错误-e symbol_name: 指定一个主可执行文件的入口点。 默认情况下,入口名称是 “start”,它在crt1.o中找到,其中包含了设置和调用main()所需的glue代码-w: 忽略所有警告信息-final_output name: 如果没有使用·-install_name·,则指定dylib的安装名称。 当编译器驱动程序调用-arch指定多个参数时,会使用这个选项。-arch_multiple: 指定链接器应该用架构名来增加错误和警告信息。 这个选项在编译器驱动程序调用多个-arch参数时使用。-twolevel_namespace_hints: 在生成的二进制文件中添加提示,只要被链接的库没有改变,这些提示就可以帮助加速dyld的运行时绑定。-dot path: 在指定的路径上创建一个包含符号依赖关系图的文件。 可以在 GraphViz 中查看 .dot 文件.-keep_relocs: 在最终的链接映像中添加基于section的重定位记录。 这些重定位记录在运行时被 dyld 忽略。-warn_stabs: 当由于编译器在BINCL/EINCL范围内置了一个bad stab符号而导致链接器不能进行BINCL/EINCL优化时,打印一个警告。-warn_commons: 每当发现object file中的tentative definition和链接的 dylib 中也有同名的外部符号时,都会打印一个警告。 这通常意味着头文件中的变量声明中缺少extern关键字。-read_only_stubs: [仅限 i386] 使最后链接image的 __IMPORT 段只读。 这个选项使程序稍微安全一些,因为 i386 fast stub中的 JMP 指令不会轻易被恶意代码覆盖。 缺点是 dyld 必须使用 mprotect() 在绑定存根时暂时使该段可写。-slow_stubs: [仅适用于i386]链接器不使用单个JMP指令stub,而是在__TEXT段创建代码,通过__DATA段的懒惰指针进行调用。-interposable_list filename: 指定的filename包含一个全局符号名的列表,这些符号名总是应该被间接访问。 例如,如果libSystem.dylib的链接使得_malloc是可互换的,那么对_malloc的调用就应该是间接的。 malloc()会经过dyld stub,并有可能间接到另一个 malloc。 如果libSystem.dylib在构建时没有将_malloc作为可替换的对象,那么如果_malloc在运行时被插入,来自libSystem的malloc的调用会被忽略(没有被插入),因为它们是直接调用。-no_function_starts: 默认情况下,链接器会在最终链接image的LINKEDIT中创建一个函数起始地址的压缩表。 这个选项可以禁止这种行为.-no_objc_category_merging: 默认情况下,当链接生成最终的镜像时,链接器会通过将类的所有category合并到类中来优化Objective-C类。 类和它的类别都必须被定义在镜像,以便进行优化。 使用此选项将禁用该行为。-objc_relative_method_list: 默认情况下,当制作最终的链接镜像时,如果目标是一个足够新的OS版本,链接器将重写ObjC方法列表,从传统的三个指针到使用三个只读的delta指针. 这个选项允许你强制使用相对方法列表,即便OS版本太低。-no_objc_relative_method_lists:默认情况下,当制作最终的链接镜像时,如果目标是一个足够新的操作系统版本,链接器将重写ObjC方法列表,从传统的三个指针到使用三个只读的delta指针。这个选项允许你强制使用传统的三个指针方法列表。-object_path_lto filename: 当执行链接时间优化(LTO)时,需要一个临时的mach-o对象文件,如果使用这个选项,临时文件将存储在指定的路径上,并在链接完成后保留。 如果没有这个选项,链接器会在链接工具完成之前选取一个路径并删除对象文件,因此调试器或dsymutil等工具将无法访问临时对象文件中的DWARF调试信息.-lto_library path: 当执行链接时间优化(LTO)时,链接器通常会相对于链接器二进制文件(…/lib/libLTO.dylib)加载libLTO.dylib。这个选项允许用户指定一个特定的libLTO.dylib的路径来代替-cache_path_lto path: 当执行增量链接时间优化(LTO)时,使用此目录作为增量重建的缓存-prune_interval_lto seconds: 当执行增量链路时间优化(LTO)时,缓存将在指定的时间间隔后进行修剪(pruned)。值为0将强制修剪,值为-1将禁止修剪-prune_after_lto seconds: 当为增量链路时间优化(LTO)修剪缓存时,缓存条目会在指定的时间间隔后被删除。-max_relative_cache_size_lto percent: 当执行增量链接时间优化(LTO)时,缓存将被修剪成不超过可用空间的这个百分比。即100的值表示缓存可能会填满磁盘,50的值表示缓存的大小将被保持在可用磁盘空间以下.-fixup_chains_section: 当使用-pie时,与-static或-preload一起使用。 告诉链接器添加一个__TEXT,__chain_starts 部分,该部分以 dyld_chained_starts_offsets 结构开始,该结构指定了指针格式和每个fixup链开始的偏移量-threaded_starts_section: 仅适用于arm64e, 当使用-pie时,与-static或-preload一起使用。告诉链接器增加一个__TEXT,__thread_starts的部分,该部分以一个32位标志字段开始,后面是一个32位的数组。 每个值都是固定链开始的偏移量。这个选项已经过时了。-page_align_data_atoms: 在开发过程中,这个选项可以用来给所有的全局变量留出空间,使每个变量都在一个单独的页上。 这在分析脏页和常驻页时很有用。 这些信息可以用来创建一个顺序文件,将常用的/肮的全局变量集中到同一个页面上。-not_for_dyld_shared_cache: 通常情况下,链接器会给以 -install_name 开头的 dylibs 添加额外的信息,这些信息以 /usr/lib 或 /System/Library/ 开头,允许 dylib 被放入 dyld 共享缓存中。 添加这个选项让链接器不添加额外的信息。
过时选项
-segalign value:-seglinkedit:-noseglinkedit:-fvmlib:-sectobjectsymbols segname sectname:-nofixprebinding:-noprebind_all_twolevel_modules:-prebind_all_twolevel_modules:-prebind_allow_overlap:-noprebind:-sect_diff_relocs treatment:-run_init_lazily:-single_module:-multi_module:-no_dead_strip_inits_and_terms:-A basefile:-b:-Sn:-Si:-Sp:-X:-s:-m:-ysymbol:-Y number:-nomultidefs:-multiply_defined_unused treatment:-multiply_defined treatment:-private_bundle:-noall_load:-seg_addr_table_filename path:-sectorder:-sectorder_detail:-lazy_framework name[,suffix]:-lazy-lx:-lazy_library path_to_library:
WWDC20-OC runtime改进
![]()
类结构体变化
在你的应用程序的磁盘上,二进制类是这样的.

首先是类对象本身,它包含了最常被访问的信息:指向元类、超类和方法缓存的指针.它还有一个指向更多数据的指针.存储额外信息的地方叫做 class_ro_t.RO代表只读,该结构体包括像类名,方法、协议和实例变量的信息.
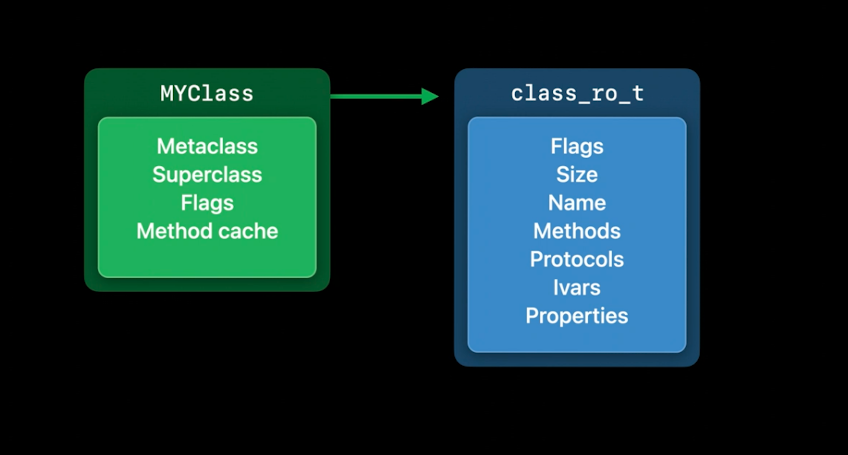
Swift类和Objective-C类共享这个基础架构,所以每个Swift类也有这些数据结构.当类第一次从磁盘加载到内存中时,它们一开始也是这样的.但是一旦使用了它们,它们就会发生变化.
在阐述具体发生什么之前先了解两个概念:
Clean Memory: 是指一旦加载后就不会改变的内存
比如class_ro_t就是clean的, 因为它是只读的.
Dirty Memory: 脏内存是指在进程运行时被改变的内存
类结构一旦被使用,就会被弄脏,因为运行时会向它写入新的数据(例如它创建了一个新的方法缓存,并从类中指向它).
Dirty Memory 要比 Clean Memory 昂贵的多, 因为只有进程在运行,它就必须一直存在; 而Clean Memory是不变的, 如果需要系统能从磁盘中重新加载它, 所以可以从内存中移除.
MacOS 中有swap脏内存的可选操作, 但是因为iOS没有使用swap,脏内存在iOS中的代价会特别大.出于这个原因,能保持干净的数据越多越好, 原来的类结构体被划分为两块.通过分离出那些永远不会改变的数据,那就可以把大部分的类数据作为干净的内存来保存.
这些数据足以让我们开始使用,但运行时需要跟踪每个类的更多信息, 所以,当一个类第一次被使用时,运行时会为它分配额外的存储空间. 这个运行时分配的存储是可读可写的数据class_rw_t.在这个数据结构中,我们存储了只有在运行时产生的新信息.例如,所有的类都会使用这些First Subclass和Next Sibling Class指针链接成一个树形结构.
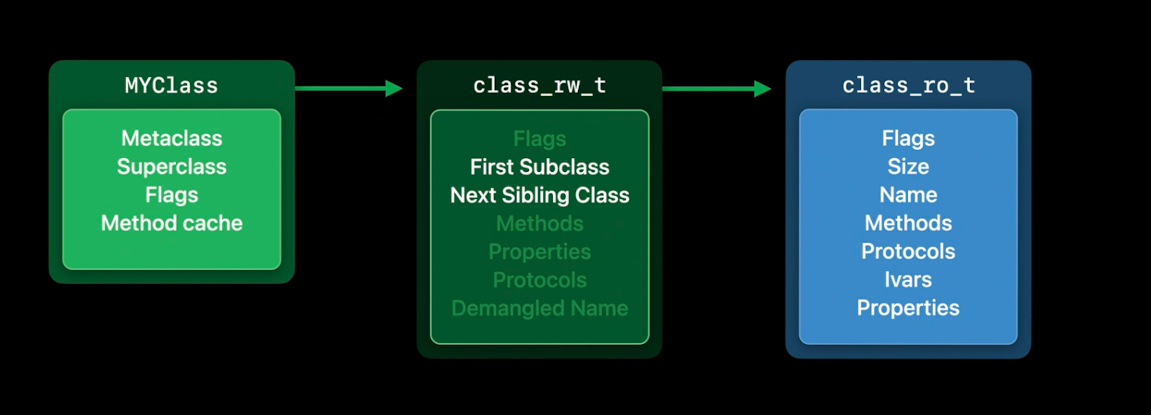 而且这允许运行时遍历当前使用的所有类,这对于无效的方法缓存很有用.但是,既然方法和属性也在只读数据中,为什么我们要在这里有方法和属性呢?嗯,因为它们可以在运行时改变.当一个Category被加载时,它可以向类中添加新的方法.而且程序员可以使用运行时API动态添加它们.由于class_ro_t是只读的,所以我们需要在
而且这允许运行时遍历当前使用的所有类,这对于无效的方法缓存很有用.但是,既然方法和属性也在只读数据中,为什么我们要在这里有方法和属性呢?嗯,因为它们可以在运行时改变.当一个Category被加载时,它可以向类中添加新的方法.而且程序员可以使用运行时API动态添加它们.由于class_ro_t是只读的,所以我们需要在class_rw_t中跟踪这些东西.
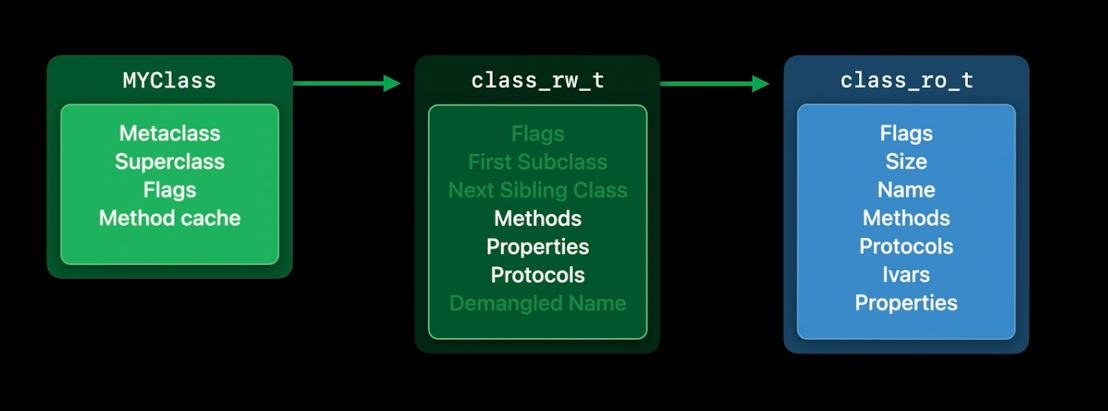
现在发现,这样做会占用不少的内存.在任何一个给定的设备中,都有很多类在使用.我们在一台iPhone上测得整个系统中大约有30MB的这些class_rw_t结构.
那么我们如何才能缩小这些呢?请记住,我们在读/写部分都需要这部分数据,因为它们可以在运行时改变.但是……检查实际设备上的使用情况,苹果发现只有10%左右的类真正改变过它们的方法.而且这个Demangled Name字段只有Swift类才会使用,除非有东西询问他们的Objective-C名称,否则Swift类也根本不需要它.所以,我们可以把那些平时不用的部分拆掉.
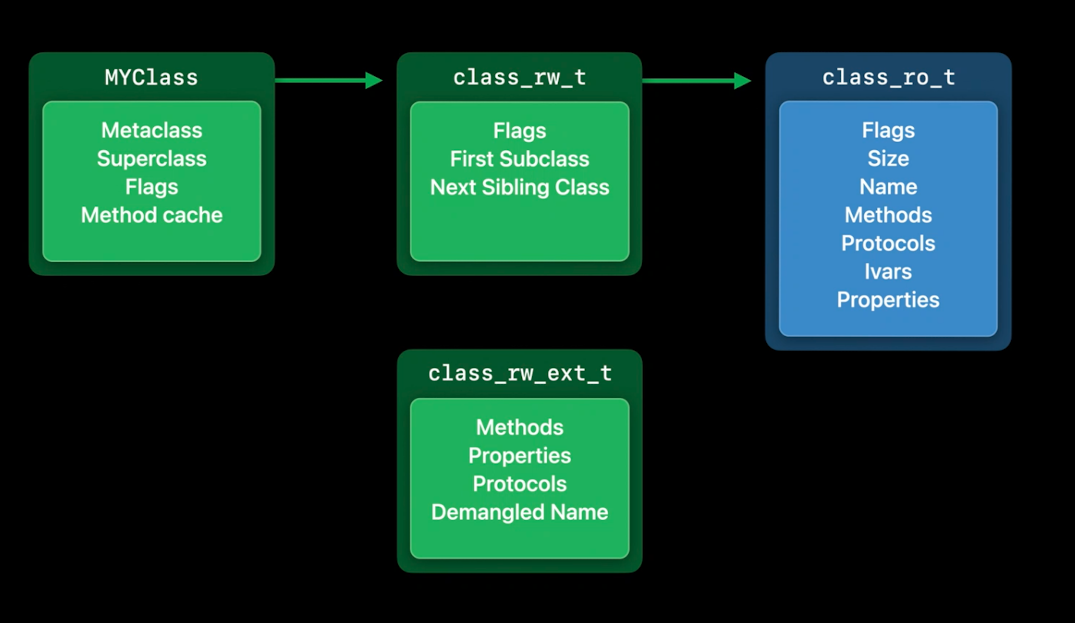
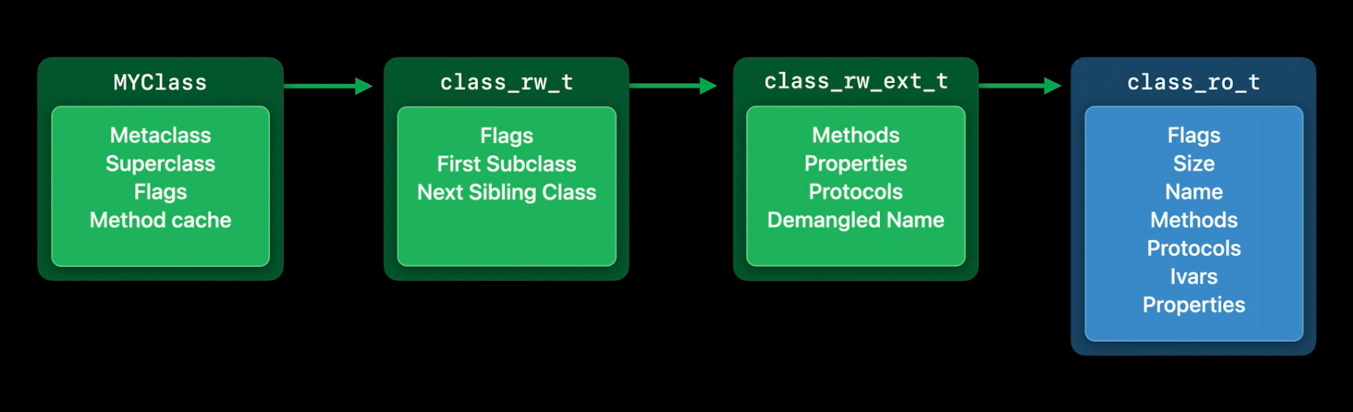
这样一来,class_rw_t的大小就减少了一半.对于那些确实需要额外信息的类,我们可以分配一个这样的扩展记录,然后把它滑到类中供其使用.大约90%的类从来不需要这些扩展数据,整个系统节省了大约14MB.这些内存现在可以用于更有成效的用途,比如存储你的应用程序的数据.
因此,你可以通过在终端中运行一些简单的命令,亲自在 Mac 上看到这一变化的影响.
# note:确认对应的App在运行
heap Mail | egrep 'class_rw|COUNT'
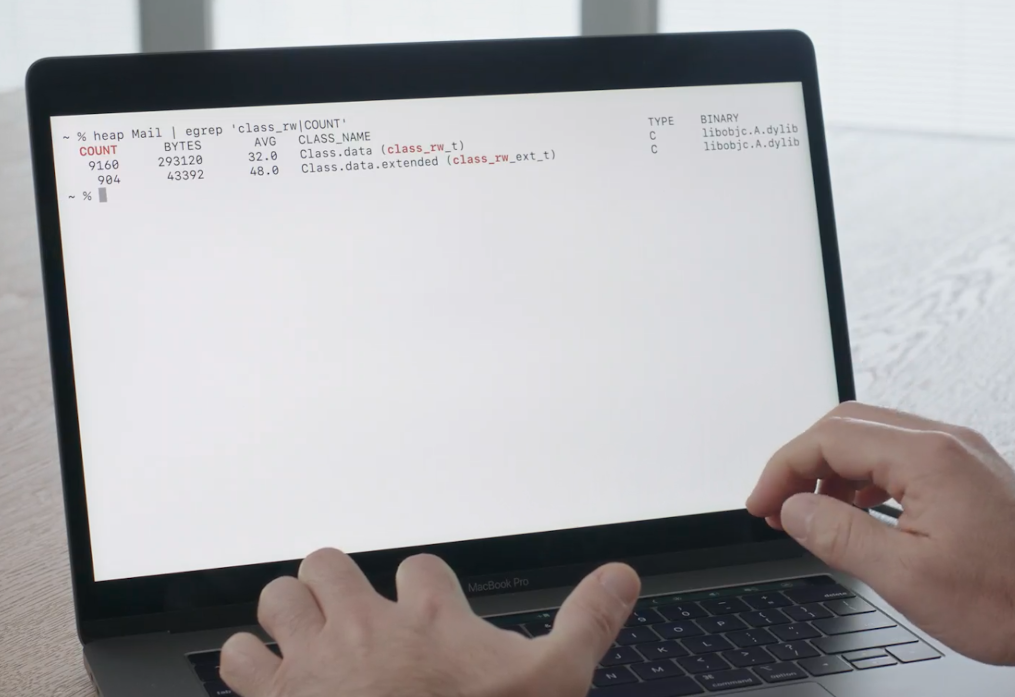
而从返回的结果中,我们可以看到,我们在邮件应用中使用了大约9000个这样的class_rw_t类型,但实际上其中只有大约十分之一,900多一点,需要使用这个扩展信息. 单邮件这一个应用我们就节省了大约25万兆的数据. 如果我们在系统范围内进行扩展,那就真正能节省了很多脏内存带来的开销.
修改之后很多从类中获取数据的代码必须同时处理那些有和没有扩展数据的类.当然,因为读取和更新这些结构的代码都在runtime内, runtime内部会为你处理所有这些操作,从外部看一切都像以前一样,只是使用更少的内存.
所以尽量使用runtime提供的API,因为这部分数据结构的更改, 任何第三方试图直接访问这些数据结构的代码在今年的操作系统版本中都会停止工作.
方法列表变化
接下来,让我们再深入了解一下这些类的数据结构,看看另一个变化:相对方法列表(relative method lists).每个类都有一个附加的方法列表.当你在一个类上写一个新方法时,它就会被添加到列表中.runtime使用这些列表来解析消息发送.
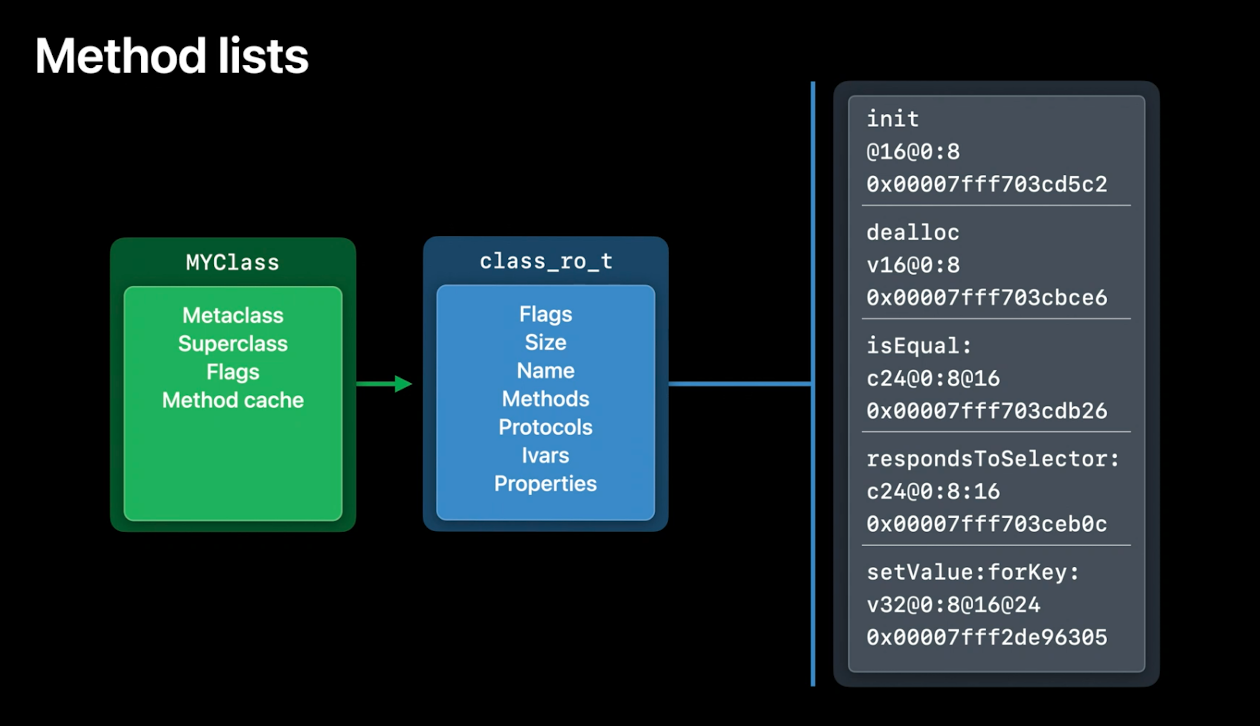
每个方法都包含三条信息:
首先是方法的名称,或者说Selector;Selector是字符串,但它们是唯一的,所以它们可以使用指针平等来比较.
其次是方法的类型编码(type encoding).这是一个表示参数和返回类型的字符串,它不是用来发送消息的,但它是运行时反省(introspection)和消息转发(forwarding)等必需的.
最后,还有一个指向方法的实现的指针–方法的实际代码.当你写一个方法时,它会被编译成一个C函数,里面有你的实现,然后条目(entry)和方法列表都指向这个函数.让我们看看一个具体的方法.
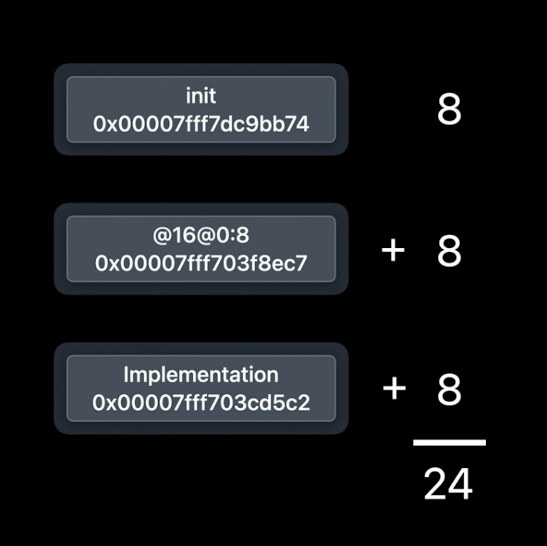
我选择了init方法.它包含了方法名、类型和实现.方法列表中的每一条数据都是一个指针.
在我们的64位系统中,这意味着每个方法表条目占用24个字节.现在这是干净的内存,但干净的内存并不是免费的.它仍然必须从磁盘加载,并且在使用时占用内存.现在这里是一个进程内内存的放大视图(NOTE:这不是按比例放大的).
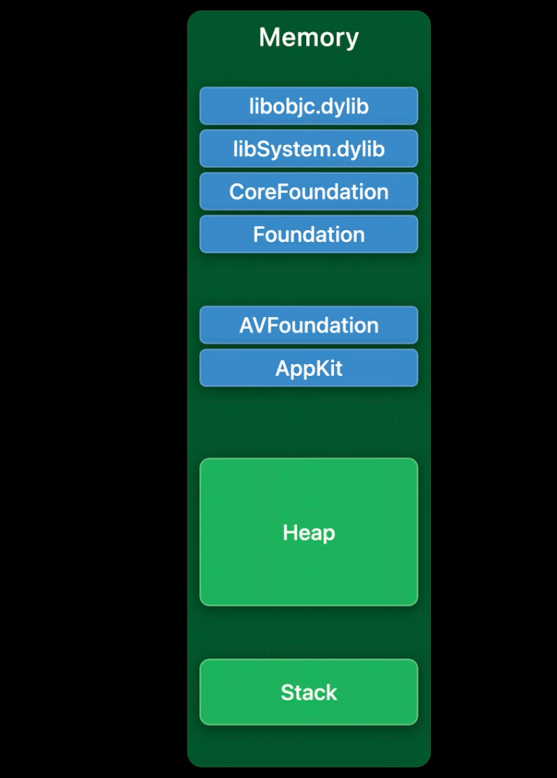
有一个很大的地址空间,需要64位来寻址.在这个地址空间内,为栈、堆以及加载到进程中的可执行文件和库或二进制映像划分出了不同的部分,这里用蓝色显示.让我们放大来看其中的一个二进制镜像.
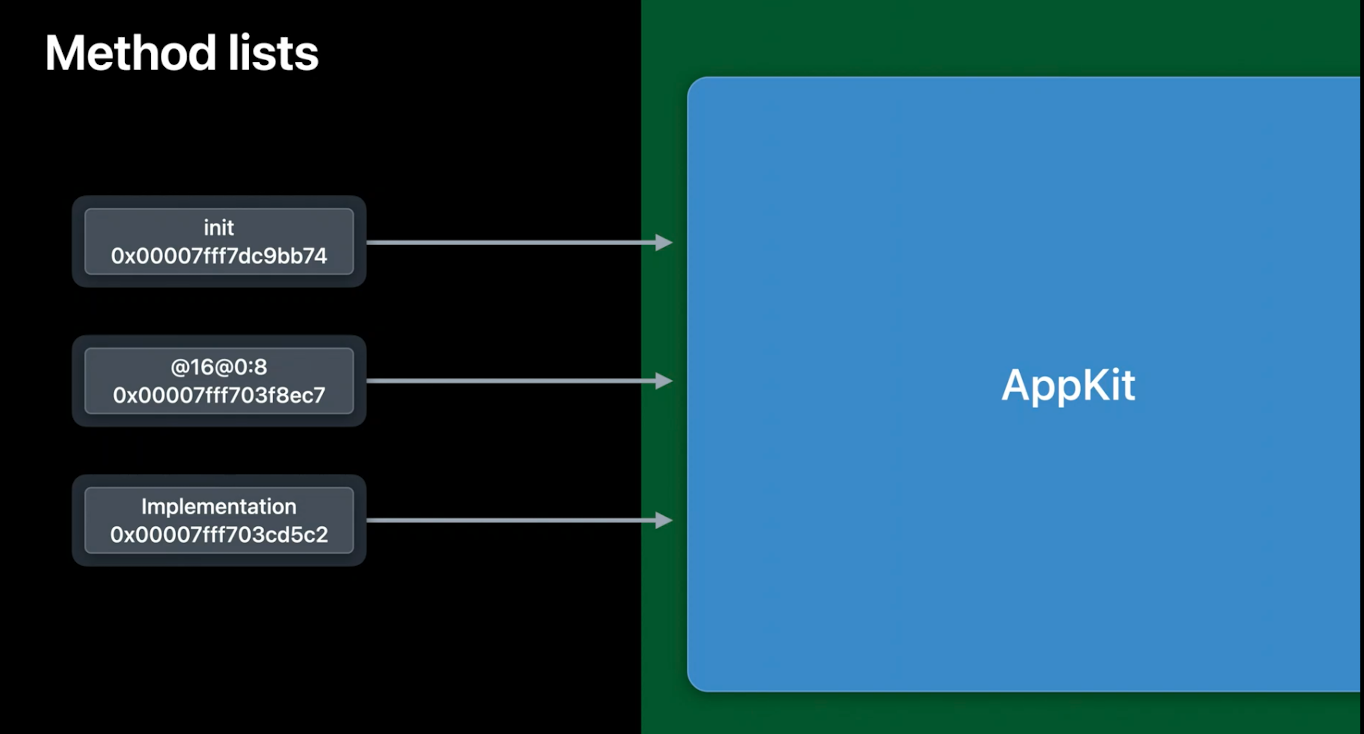 这里我们显示了三个方法表项指向其二进制中的位置.这向我们展示了另一个成本.二进制图像可以加载到内存中的任何地方,这取决于动态链接器决定把它放在哪里.这意味着链接器需要在加载时将指针解析到镜像中,并将其fix up为指向其在内存中的实际位置.而这也是有代价的.
现在,请注意,一个来自二进制的类方法条目永远只指向该二进制内的方法实现.没有办法让一个方法的元数据在一个二进制中,而实现它的代码在另一个二进制中.这意味着方法列表条目实际上不需要能够引用整个64位地址空间.它们只需要能够引用自己二进制中的函数,而且这些函数总是在附近.因此,他们可以在二进制中使用一个32位的相对偏移,而不是一个绝对的64位地址.
这也是苹果今年做的一个改变.
这里我们显示了三个方法表项指向其二进制中的位置.这向我们展示了另一个成本.二进制图像可以加载到内存中的任何地方,这取决于动态链接器决定把它放在哪里.这意味着链接器需要在加载时将指针解析到镜像中,并将其fix up为指向其在内存中的实际位置.而这也是有代价的.
现在,请注意,一个来自二进制的类方法条目永远只指向该二进制内的方法实现.没有办法让一个方法的元数据在一个二进制中,而实现它的代码在另一个二进制中.这意味着方法列表条目实际上不需要能够引用整个64位地址空间.它们只需要能够引用自己二进制中的函数,而且这些函数总是在附近.因此,他们可以在二进制中使用一个32位的相对偏移,而不是一个绝对的64位地址.
这也是苹果今年做的一个改变.
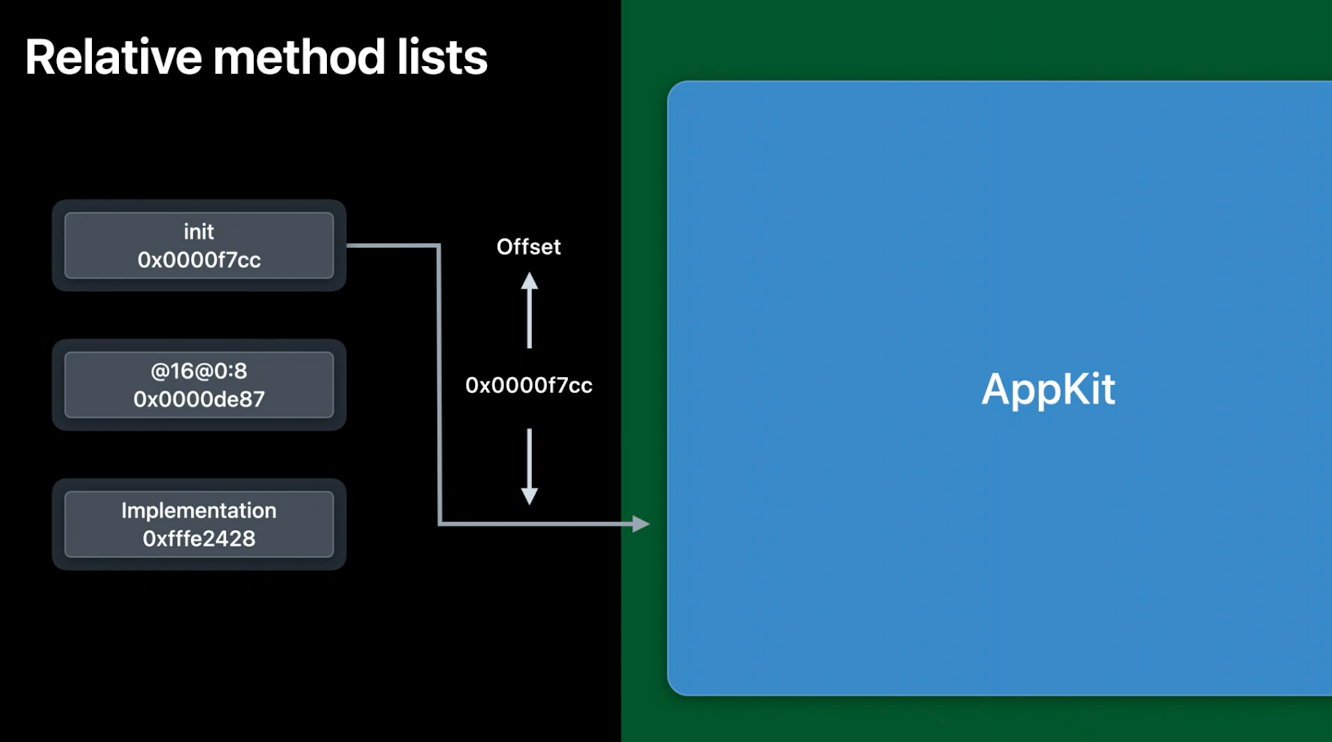
这有几个好处.首先,无论image在哪里加载到内存中,偏移量始终是相同的,所以它们不必在从磁盘加载后进行修正. 而且因为它们不需要被修正起来, 它们可以被保存在真正的只读内存中,这样更安全.当然,32位的偏移意味着我们已经将64位平台上所需的内存量减少了一半.

苹果工程师在一个典型的iPhone上测得关于BOMB的这些方法的系统范围, 节省了40MB.
但是swizzling呢?二进制中的方法列表现在不能引用整个地址空间.但是,如果你swizzle一个可以在任何地方实现的方法,而且,我们刚刚说过,我们希望保持这些方法列表只读.为了处理这个问题,苹果也提供了一个全局表,将方法映射到它们被swizzle的实现上.Swizzling是很少见的.绝大多数方法实际上从未被swizzle过,所以这个表最终不会变得很大.更好的是这个表很紧凑.
我们知道内存是按页分配的, 在旧的方法列表实现中, swizzle一个方法会弄脏它所在的整个页面,导致swizzle一次就会弄脏很多千字节的内存.有了表,我们只需为一个额外的表条目付出代价.一如既往,这些变化对你来说是看不见的,一切都会像以前一样继续工作.这些相对方法列表在今年晚些时候推出的新的操作系统版本上得到了支持.
当你使用相应的最小部署目标进行构建时,工具会自动在你的二进制文件中生成相对的方法列表,如果你需要针对老版本的OS,不用担心, Xcode也会生成老式的方法列表格式.你仍然可以从操作系统本身的构建中获得新的相对方法列表的好处,而且系统在同一应用程序中同时使用两种格式也没有问题.不过如果你能针对今年的OS版本构建,你会得到更小的二进制文件和更少的内存使用.
这在Objective-C或Swift中是一个普遍不错的提示.最小部署目标并不只是关于哪些SDK API可以给你使用.当Xcode知道它不需要支持旧的操作系统版本时,它通常可以发出更好的优化代码或数据.我们理解你们中的许多人需要支持旧的OS版本,但这也是为什么无论何时增加部署目标都是一个好主意的原因.现在,有一件事需要注意,那就是使用比你打算使用的部署目标更新的部署目标进行构建.Xcode通常会防止这种情况发生,但也有可能漏掉,特别是当你在其他地方构建自己的库或框架,然后将它们带进来的时候.当运行在旧的操作系统上时,旧的运行时会看到这些相对方法,但它对它们一无所知,所以它会尝试像解释旧式的基于指针的方法一样解释它们.这意味着它将尝试把一对32位的字段作为64位的指针来读取.结果是两个整数被粘在一起作为一个指针,这是一个无意义的值,如果真的使用它,肯定会崩溃.你可以通过运行时读取方法信息时的崩溃来识别这种情况的发生,一个坏的指针看起来就像两个32bit的值被平滑在一起,就像这个例子.
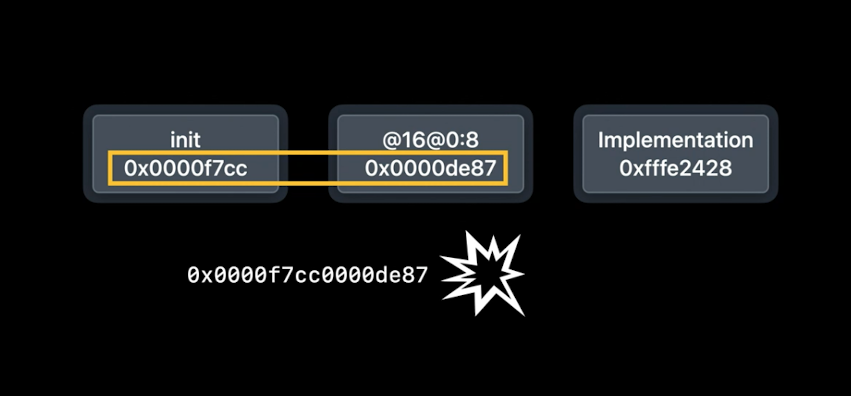
如果你运行的代码挖掘这些结构来读出值,那这段代码就会出现和这些旧运行时一样的问题,当用户升级设备时,App就会崩溃.所以,还是不要这样做–使用API.不管底层的东西怎么变,那些API都能继续工作. 例如,有一些函数,给定一个方法指针就会返回其字段的值.
Tagged Pointer变化
我们再来探讨一下今年即将到来的一个变化:ARM64上Tagged Pointer格式的变化.首先,我们需要知道什么是Tagged Pointer.
我们将在这里探索底层真正的实现,但不要担心–就像我们谈过的其他事情一样,你不需要知道这些.它只是很有趣–也许能帮助你更好地理解你的内存使用情况.让我们从普通对象指针的结构开始.
通常,当我们看到这些指针时,它们被打印成这些大的十六进制数字.我们在前面看到了一些这样的东西.让我们把它分解成二进制表示.
 我们有64位的空间.然而,我们并没有真正使用所有这些位.只有中间的几位在真正的对象指针中被设置.低位总是0,因为对齐要求:对象必须总是位于一个指针大小的倍数的地址中.高位总是0,因为地址空间是有限的:我们实际上不会用到2^64.这些高位和低位总是0.
所以让我们从这些始终为0的位子中挑出一个位子,让它变成1.这可以立即告诉我们这不是一个真正的对象指针,然后我们可以给所有其他位子赋予一些其他的意义.我们称之为
我们有64位的空间.然而,我们并没有真正使用所有这些位.只有中间的几位在真正的对象指针中被设置.低位总是0,因为对齐要求:对象必须总是位于一个指针大小的倍数的地址中.高位总是0,因为地址空间是有限的:我们实际上不会用到2^64.这些高位和低位总是0.
所以让我们从这些始终为0的位子中挑出一个位子,让它变成1.这可以立即告诉我们这不是一个真正的对象指针,然后我们可以给所有其他位子赋予一些其他的意义.我们称之为Tagged Pointer.
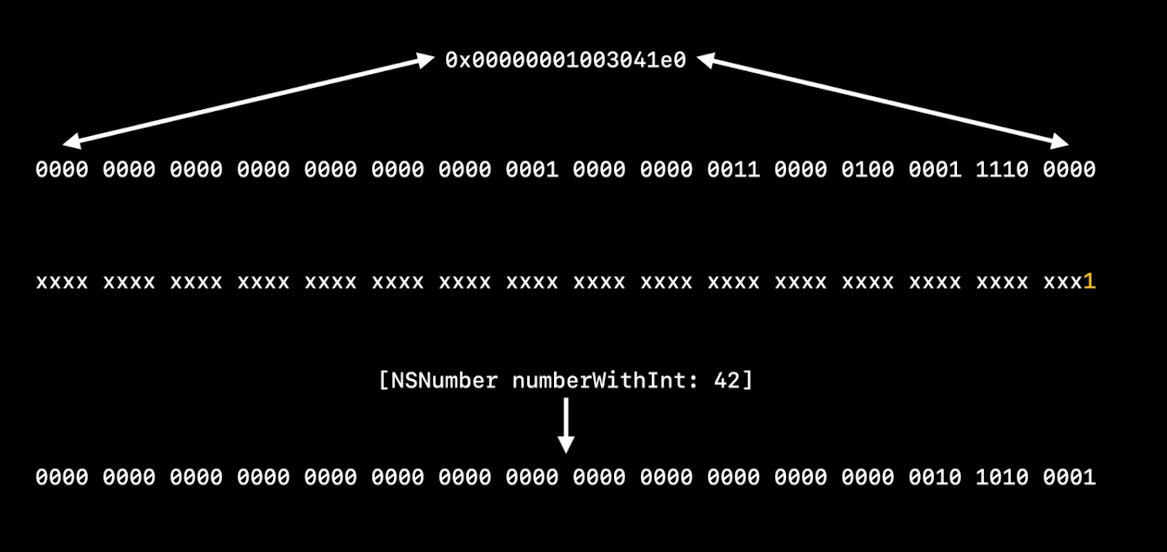
例如,我们可以在其他位中塞入一个数值.只要我们想教NSNumber如何读取这些位,并让运行时适当地处理标签指针,系统的其他部分就可以把这些东西当做对象指针来处理,永远不会知道其中的区别.而这也为我们节省了为每一种这样的情况分配一个微小的数字对象的开销,这可能是一个重大的改进.这些值实际上是通过将它们与一个进程启动时初始化的随机值相结合来混淆的, 这是一种安全措施,它使伪造标记指针值变得困难.

在接下来的讨论中,我们将忽略这一点,因为它只是在上面增加了一层.只是要注意,如果你真的试图在内存中查看这些值,它们会被扰乱.所以这就是Intel上标记指针的完整格式.低位被设置为1,表示这是一个Tagged Pointer.正如我们讨论过的,对于一个真实的指针来说,这个位必须始终为0,所以这让我们可以区分它们.接下来的3位是标签号.这表示标记指针的类型.例如,3表示它是一个NSNumber,6表示它是一个NSDate.由于我们有3个标签位,所以有8种可能的标签类型.其余的位是有效载荷(payload), 这是特定类型可以随意使用的数据.对于标记的NSNumber,这是实际的数字.
 现在标签7有一个特殊情况.这表示一个扩展标签.扩展标签使用下一个八位来对类型进行编码,允许多出256个标签类型,但代价是减少有效载荷.这使得我们可以将标签指针用于更多的类型,只要它们能够将其数据装入更小的空间.这被用于像标记
现在标签7有一个特殊情况.这表示一个扩展标签.扩展标签使用下一个八位来对类型进行编码,允许多出256个标签类型,但代价是减少有效载荷.这使得我们可以将标签指针用于更多的类型,只要它们能够将其数据装入更小的空间.这被用于像标记UlColor或NSIndexSet这样的东西.如果这对你来说非常方便,你可能会失望地听到只有运行时维护者–也就是苹果–可以添加Tagged Pointer类型.
但如果你是一个Swift程序员,你会很高兴地知道你可以创建自己的标签指针类型. 如果你曾经使用过一个具有关联值的枚举,那就是一个类似于Tagged Pointer的类.Swift运行时将枚举判别器存储在关联值有效载荷的备用位中.更重要的是,Swift对值类型的使用实际上使Tagged Pointer变得不那么重要了,因为值不再需要完全是指针大小.例如,Swift的UUID类型可以是两个字,并保持在内联,而不是分配一个单独的对象,因为它不适合在一个指针里面.
这就是英特尔上的标记指针.我们来看看ARM.在ARM64上,苹果把事情翻转过来了.
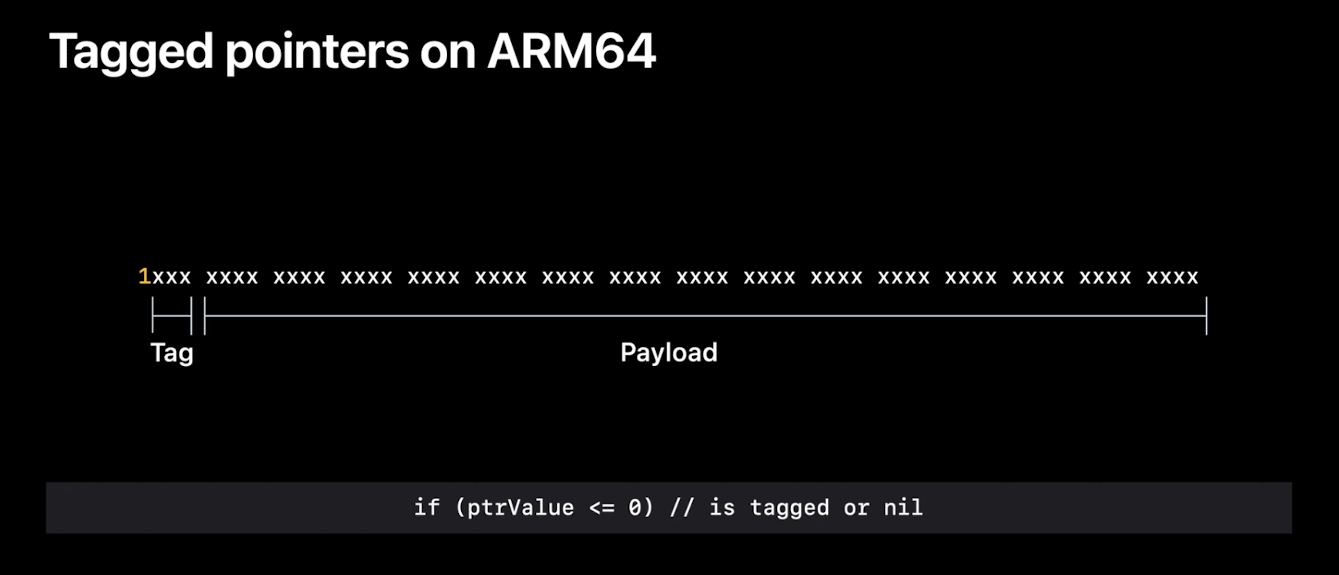
最高位(而不是最低位)被设置为1,表示一个Tagged Pointer.然后标签号在接下来的三个位中出现.然后,有效载荷使用剩余的位.为什么苹果在ARM上使用顶部位来指示标记指针,而不是像在英特尔上那样使用底部位?嗯,这实际上是对objc_msgSend的一个小小的优化.苹果希望msgSend中最常见的路径尽可能快.而最常见的路径是一个普通的指针.我们有两种不太常见的情况:Tagged Pointer和nil.事实证明,当我们使用最高位时,我们可以通过一次比较来检查这两种情况.而且在msgSend中,这样就为常见的情况节省了一个条件分支,而不是分别检查nil和Tagged Pointer.就像在英特尔上,对标签7表示一个特殊的情况,接下来的8位被用作扩展标签,然后剩下的位被用于有效载荷.或者说这其实是旧的格式,在iOSl3中使用.在今年的版本中.我们把东西移动了一下! 标签位保持在最高位,因为那个msgSend的优化还是非常有用的.标签号现在移到了最下面的三个位.
扩展标签如果使用,则占据标签位后的高八位.

为什么要这样做呢?好吧,我们再考虑一个普通的指针.我们现有的工具,比如动态链接器,由于ARM的一个名为Top Byte Ignore的特性,忽略了指针的前8位.而我们会把扩展标签放在Top Byte Ignore位.对于一个对齐的指针来说,底部三个位总是0.但我们可以通过在指针中添加一个小数字来改变这一点.

我们将添加7来将低位设置为1.请记住,7 表示这是一个扩展标记.这意味着我们实际上可以将上面的这个指针放入一个扩展标签指针有效载荷中.结果就是一个标签指针,其有效载荷中包含一个普通指针.为什么这很有用呢?嗯,它开启了标记指针引用二进制中的常量数据的能力,例如字符串或其他数据结构,否则它们将不得不占用肮脏的内存.当然,现在这些变化意味着,当iOSl4今年晚些时候发布时,直接访问这些位的代码将不再工作.像这样的位检查在过去是可以工作的,但在未来的操作系统上会给你错误的答案,你的App会开始神秘地破坏用户数据.所以不要使用依赖于我们刚才谈到的任何代码.相反,你大概可以猜到我要说什么:也就是使用API.像isKindOfClass:这样的类型检查在旧的标记指针格式上工作,它们将继续在新的标记指针格式上工作. 所有的NSString或NSNumber方法都能继续工作.这些标记指针中的所有信息都可以通过标准的API来检索.
值得注意的是,这也适用于CF类型.苹果表示他们不想隐藏任何东西,也绝对不想破坏任何人的Apps. 当这些细节没有暴露出来的时候,只是因为他们需要保持灵活性来进行这样的改变,只要你的App不依赖这些内部细节,你的App就会继续正常工作.
那么,我们来总结一下.在这次Session中,我们已经看到了一些幕后的改进,这些改进缩小了我们运行时的开销,将更多的内存留给你和你的用户.你不需要做任何事情就能获得这些改进–除了可能考虑提高你的deployment target.
xcode编译耗时优化
![]()
前戏太长, 容易疲软. 几乎每一个iOSer都会时不时地遭受Xcode构建时间过长的困扰. 它直接导致生产率的降低,并拖慢了整个团队的开发进程, 影响coding辛福感.
跟做app性能提升类似, 优化编译时间在很大程度上需要的是耐心、严谨和毅力,要仔细、持续地测量. 是一个逐步消除噪音,集中精力去分析一个信号的过程.
环境配置
Apple Swift version 5.2.4 (swiftlang-1103.0.32.9 clang-1103.0.32.53)
Target: x86_64-apple-darwin19.5.0
量化
在开始之前先来看看如何量化这部分的数据. 一方面这些数据帮助我们更精确地度量优化的效果,集中精力focus具体的可优化项; 另一方面或许你的晋升或KPI总结里需要这部分内容.
直接查看Report Navigator中的日志, 是获取总的编译耗时最直接简单的方式.
另外也可以通过配置ShowBuildOperationDuration来开启activity viewer中的编译耗时视图
defaults write com.apple.dt.Xcode ShowBuildOperationDuration YES
当然这只能查看单个总耗时, 如果需要粒度更细的数据可以使用
Product->Perform Action->Build With Timing Summary编译工程(好像并没用),
或者添加命令行编译参数-showBuildTimingSummary
xcodebuild -project 'xxx.xcodeproj' \
-scheme 'xxx' \
-configuration 'Debug' \
-sdk 'iphonesimulator' \
-showBuildTimingSummary \
clean build
这样就可以获取每个阶段的耗时了, 然后针对每个耗时较长的阶段进行优化.
Build Timing Summary
CompileSwiftSources (4 tasks) | 141.310 seconds
CompileStoryboard (29 tasks) | 70.919 seconds
CompileAssetCatalog (2 tasks) | 26.859 seconds
PhaseScriptExecution (5 tasks) | 8.331 seconds
CodeSign (7 tasks) | 7.136 seconds
CompileXIB (21 tasks) | 6.603 seconds
Ld (4 tasks) | 2.880 seconds
Ditto (28 tasks) | 0.197 seconds
CompileC (3 tasks) | 0.134 seconds
LinkStoryboards (2 tasks) | 0.111 seconds
Touch (4 tasks) | 0.012 seconds
** BUILD SUCCEEDED ** [195.974 sec]
Other Swift Flags
如果Swift是编译瓶颈, 还可以通过添加编译器参数来获取更精确的信息
-driver-time-compilation-Xfrontend -debug-time-compilation-Xfrontend -debug-time-function-bodies 或 -Xfrontend -warn-long-function-bodies=xxx-Xfrontend -debug-time-expression-type-checking 或 -Xfrontend -warn-long-expression-type-checking=xxx-Xfrontend -print-stats-Xfrontend -print-clang-stats-Xfrontend -print-stats -Xfrontend -print-inst-counts
比如通过-driver-time-compilation获取Driver Job的耗时
xcodebuild -project 'clutter.xcodeproj' \
-scheme 'clutter' \
-configuration 'Debug' \
-sdk 'iphonesimulator' \
clean build \
OTHER_SWIFT_FLAGS="-driver-time-compilation"
执行后就可以从日志中提取相关数据.
===-------------------------------------------------------------------------===
Driver Compilation Time
===-------------------------------------------------------------------------===
Total Execution Time: 0.0023 seconds (0.6612 wall clock)
---User Time--- --System Time-- --User+System-- ---Wall Time--- --- Name ---
0.0002 ( 21.8%) 0.0002 ( 18.3%) 0.0005 ( 19.8%) 0.1845 ( 27.9%) {compile: TestViewController.o <= TestViewController.swift }
0.0003 ( 27.5%) 0.0004 ( 31.7%) 0.0007 ( 30.0%) 0.1641 ( 24.8%) {compile: TestSwiftObject.o <= TestSwiftObject.swift }
0.0001 ( 8.1%) 0.0000 ( 2.3%) 0.0001 ( 4.7%) 0.1481 ( 22.4%) {merge-module: clutter.swiftmodule <= TestS.o TestSwiftObject.o TestViewController.o}
0.0003 ( 31.3%) 0.0006 ( 43.2%) 0.0009 ( 38.2%) 0.1435 ( 21.7%) {compile: TestS.o <= TestS.swift }
0.0001 ( 11.3%) 0.0001 ( 4.4%) 0.0002 ( 7.3%) 0.0210 ( 3.2%) {generate-pch: <= clutter-Bridging-Header.h}
0.0010 (100.0%) 0.0013 (100.0%) 0.0023 (100.0%) 0.6612 (100.0%) Total
甚至可以获取某个函数或者表达式类型检查的耗时.
xcodebuild -project 'clutter.xcodeproj' \
-scheme 'clutter' \
-configuration 'Debug' \
-sdk 'iphonesimulator' \
clean build \
OTHER_SWIFT_FLAGS="-Xfrontend -debug-time-expression-type-checking \
-Xfrontend -debug-time-function-bodies" \
| grep -o "^\d*.\d*ms\t[^$]*$" \
| awk '!visited[$0]++' \
| sed -e "s|$(pwd)/||" \
| sort -rn \
| head -5
0.60ms clutter/TestViewController.swift:15:19 instance method viewDidLoad()
0.51ms clutter/TestViewController.swift:16:15
0.02ms clutter/TestSwiftObject.swift:11:33 initializer init()
0.02ms clutter/TestS.swift:12:9 getter aaa
0.02ms TestSymbol/TestB.swift:12:9 getter b
可视化工具
上面都是一些日志输出的量化方式需要自己从日志中提取信息, 下面介绍几个可视化工具.
Profiler - Counter & perf
Instruments.app内置了一个Counters工具, 可以通过 Xcode => Open Developer Tool => Instruments => Counters 开启. 不过该工具会记录所有进程的数据, 干扰项比较多
perf 是一款Linux下的profiler. 可以直接在命令行中使用它.
perf record -e cycles -c 10000 --call-graph=lbr swiftc t.swift
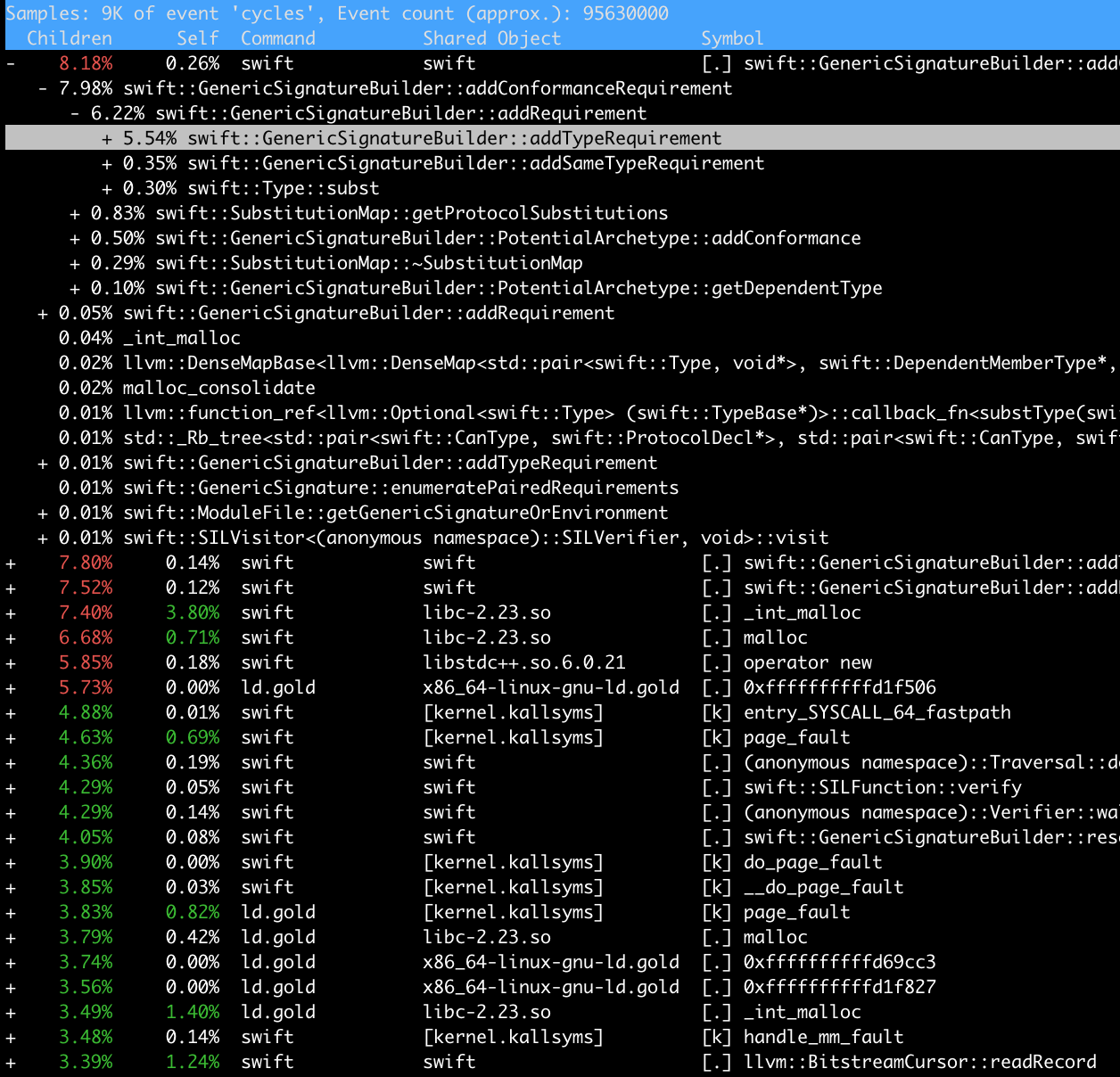
这是一款统计每个target编译耗时的工具.
# 安装
gem install xcode-build-times
# 插入 build phases 脚本
xcode-build-times install $PROJECT_PATH
# 收集数据
xcode-build-times generate
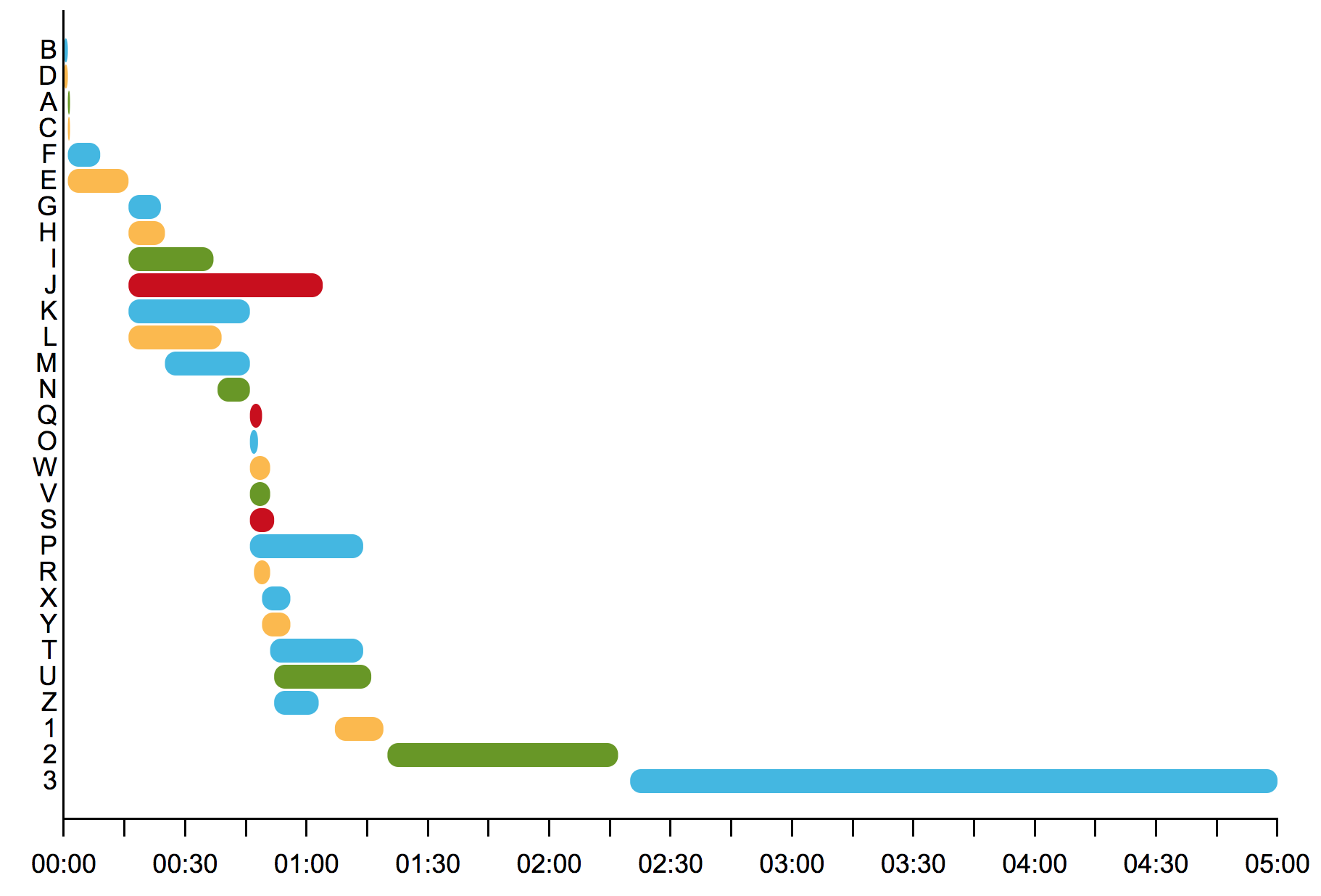
XCLogParser是一款可以解析SLF格式(存储Xcode build 和 test日志- xcactivitylog)的命令行工具. 这个工具提取的reporter很详细(强烈推荐).
# 工具安装
brew install xclogparser
# 日志解析
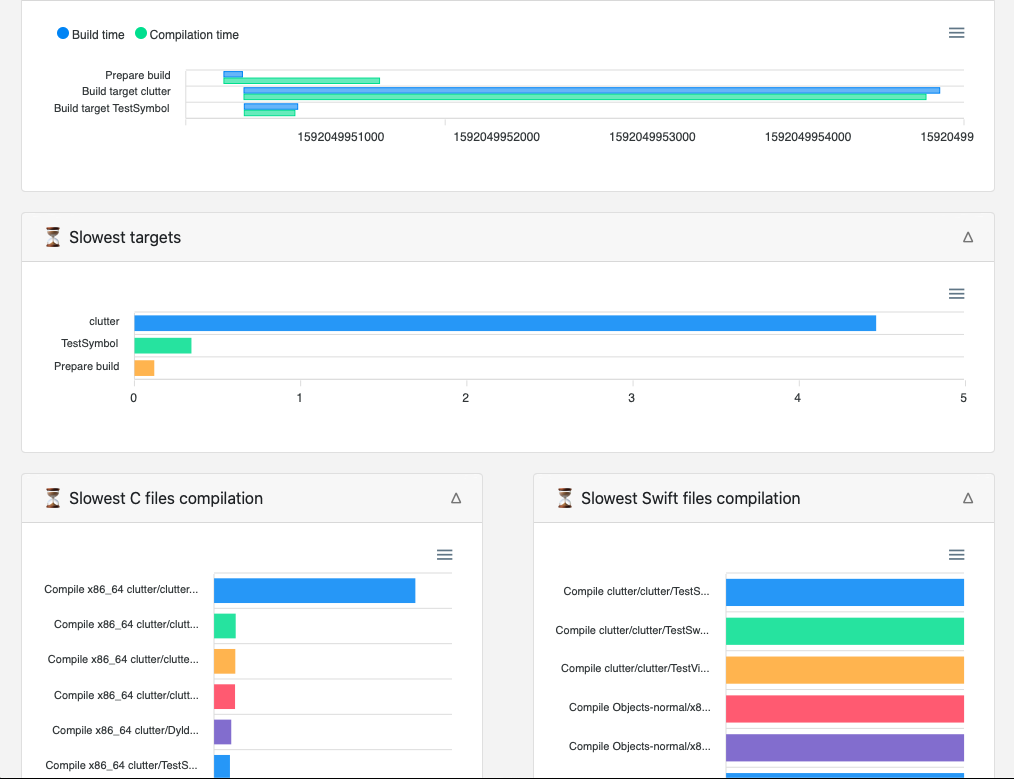
xclogparser parse --project xxx.xcodeproj --reporter html
优化内容
设置项优化
DEBUG编译模式ONLY_ACTIVE_ARCH设置为Yes.
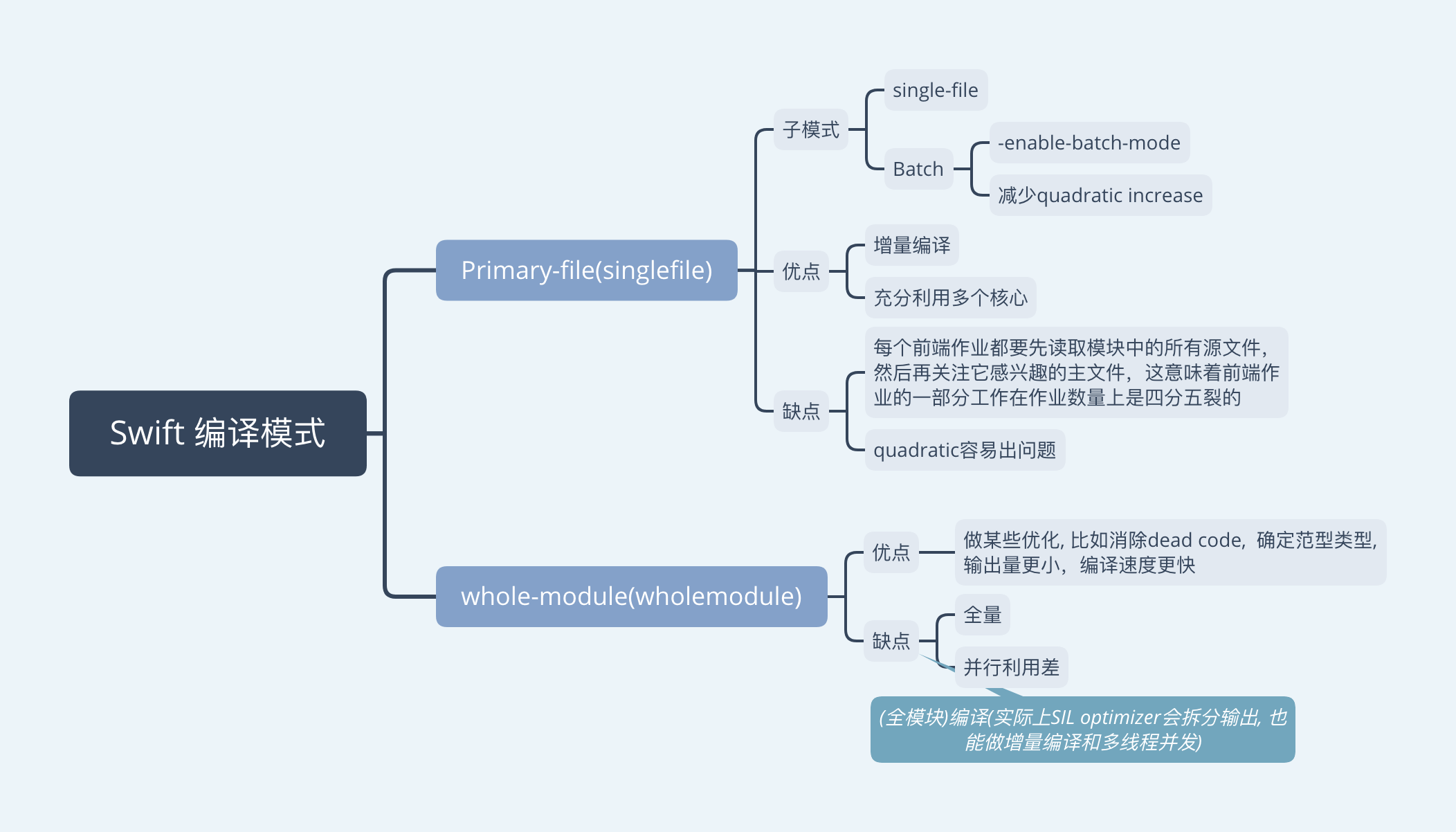
设置SWIFT_COMPILATION_MODE, Debug:Incremental, Release:Whole Module.
swift的编译前端很大不同有这两种编译模式决定
SWIFT_OPTIMIZATION_LEVEL, Debug: No Optimization, Release: Optimize for Speed
DEBUG_INFORMATION_FORMAT Debug: DWARF, Release: DWARF with dSYM
优化Search path
源码优化
控制代码粒度(比如给每个实体单独使用一个文件,为你的类、结构、枚举、扩展等使用正确的访问修饰符), 降低文件修改造成的影响, 减少rebuild的范围.
forward declaration, 使用@class而不是 #import.
正确使用pch文件
移除无用代码
预编译相关依赖
使用代码而不是xib或者Storyboard
表达式和函数优化
这里可以执行
swiftc -Xfrontend -debug-time-function-bodies xxx.swift
查看这两种方式的编译耗时.
- 减少类型推断
func typeAnnotaions() {
let arr: [String] = ["a", "b", "c", "d"]
print(arr)
}
func noTypeAnnotaions() {
let arr = ["a", "b", "c", "d"]
print(arr)
}
/*****************************
0.24ms TestSwiftA.swift:12:10 instance method typeAnnotaions()
1.79ms TestSwiftA.swift:16:10 instance method noTypeAnnotaions()
*/
1. 避免空操作
```swift
func nilCoalescing() {
let string: String? = ""
if let _ = string{
/* string has value */
}else{
/* string is nil*/
}
}
func noNilCoalescing() {
let string: String? = ""
let _ = string ?? ""
}
/*****************************
2.28ms TestSwiftA.swift:21:10 instance method nilCoalescing()
0.98ms TestSwiftA.swift:29:10 instance method noNilCoalescing()
*/
```
1. `if-else` 比三元运算符`?:`要快一点
2. 提前计算结果
```swift
func preCompute() {
let num: Int = 3600
print(num)
}
func noPreCompute() {
let num: Int = 60 * 60
print(num)
}
/*****************************
2.03ms TestSwiftA.swift:49:10 instance method preCompute()
67.48ms TestSwiftA.swift:53:10 instance method noPreCompute()
*/
append并没有比+更快
func arrPSymbol() {
var arr1 = ["a"]
let arr2 = ["b"]
arr1 += arr2
print(arr1)
}
func arrAppend() {
var arr1 = ["a"]
let arr2 = ["b"]
arr1.append(contentsOf: arr2)
print(arr1)
}
/***********************
25.72ms TestSwiftA.swift:75:10 instance method arrPSymbol()
27.89ms TestSwiftA.swift:81:10 instance method arrAppend()
*/
- 三种lazy property的写法也并不如同网上说的
private(set) lazy var propertyColors: [UIColor] = [
UIColor(red: 86/255, green: 84/255, blue: 124/255, alpha: 1),
UIColor(red: 80/255, green: 88/255, blue: 92/255, alpha: 1),
UIColor(red: 126/255, green: 191/255, blue: 189/255, alpha: 1),
UIColor(red: 161/255, green: 77/255, blue: 63/255, alpha: 1),
UIColor(red: 235/255, green: 185/255, blue: 120/255, alpha: 1),
UIColor(red: 100/255, green: 126/255, blue: 159/255, alpha: 1),
UIColor(red: 160/255, green: 209/255, blue: 109/255, alpha: 1),
]
private let closureColors = { () -> [UIColor] in
let colors = [
UIColor(red: 86/255, green: 84/255, blue: 124/255, alpha: 1),
UIColor(red: 80/255, green: 88/255, blue: 92/255, alpha: 1),
UIColor(red: 126/255, green: 191/255, blue: 189/255, alpha: 1),
UIColor(red: 161/255, green: 77/255, blue: 63/255, alpha: 1),
UIColor(red: 235/255, green: 185/255, blue: 120/255, alpha: 1),
UIColor(red: 100/255, green: 126/255, blue: 159/255, alpha: 1),
UIColor(red: 160/255, green: 209/255, blue: 109/255, alpha: 1),
]
return colors
}
private(set) lazy var funcColors: [UIColor] = _createColors()
private func _createColors() -> [UIColor] {
return [
UIColor(red: 86/255, green: 84/255, blue: 124/255, alpha: 1),
UIColor(red: 80/255, green: 88/255, blue: 92/255, alpha: 1),
UIColor(red: 126/255, green: 191/255, blue: 189/255, alpha: 1),
UIColor(red: 161/255, green: 77/255, blue: 63/255, alpha: 1),
UIColor(red: 235/255, green: 185/255, blue: 120/255, alpha: 1),
UIColor(red: 100/255, green: 126/255, blue: 159/255, alpha: 1),
UIColor(red: 160/255, green: 209/255, blue: 109/255, alpha: 1),
]
}
/*
0.03ms TestSwiftA.swift:93:27 getter propertyColors
0.01ms TestSwiftA.swift:93:27 setter propertyColors
0.03ms TestSwiftA.swift:93:27 _modify accessor propertyColors
===============
0.01ms TestSwiftA.swift:103:17 getter closureColors
===============
0.01ms TestSwiftA.swift:117:27 getter funcColors
0.01ms TestSwiftA.swift:117:27 setter funcColors
0.01ms TestSwiftA.swift:117:27 _modify accessor funcColors
0.02ms TestSwiftA.swift:119:18 instance method _createColors()
*/
工程改进
- 组件化(单组件开发, 减少开发依赖)
- 使用静态库/动态库(对于组件多的大型工程, 这里提升应该是非常可观的)
- 优化Run Script phases
- 控制模块拆分粒度(比如颗粒度更细的模块, 可以有效利用多任务)
工具或其他
- 编译器改进
- Buck/Bazel
- CCache(缓存)
- distcc(分布式编译工具)
- Preview(Swift UI), HotReload(Flutter).
- 升级硬件
参考文档